给网友们整理python代理工具mitmproxy相关的编程文章,网友宋晨希根据主题投稿了本篇教程内容,涉及到python、mitmproxy、python代理工具mitmproxy使用指南相关内容,已被257网友关注,如果对知识点想更进一步了解可以在下方电子资料中获取。
python代理工具mitmproxy使用指南
前言
mitmproxy 是 man-in-the-middle proxy 的简称,译为中间人代理工具,可以用来拦截、修改、保存 HTTP/HTTPS 请求。以命令行终端形式呈现,操作上类似于Vim,同时提供了 mitmweb 插件,是类似于 Chrome 浏览器开发者模式的可视化工具。
它是基于Python开发的开源工具,最重要的是它提供了Python API,你完全可以通过Python代码来控制请求和响应,这是其它工具所不能做到的,这点也是我喜欢这个工具的原因之一。
安装
sudo pip3 install mitmproxy
启动
mitmproxy #或者指定端口 mitmproxy -p 8888
启动 mitmproxy 之后,默认开启8080端口, mitmproxy 命令不支持Windows平台,需要使用 mitmdump 或者 mitmweb 命令代替。Windows系统也可以在官网下载它的EXE文件进行安装。
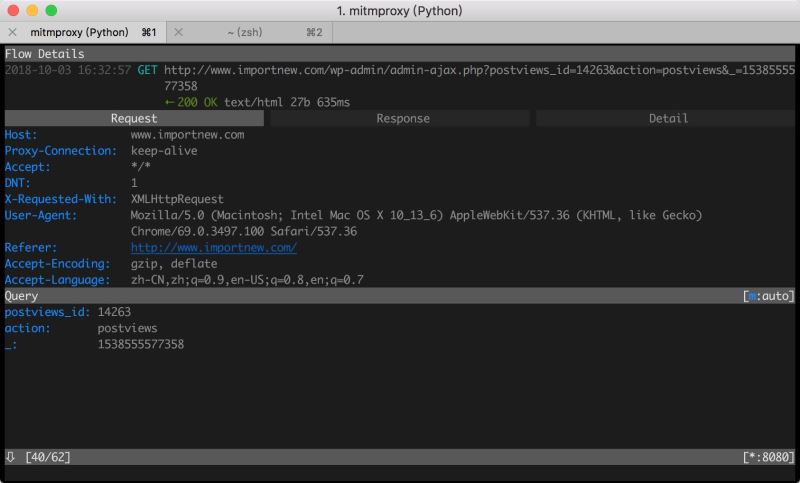
手机或者浏览器设置好代理之后,就可以进行抓包分析了,打开浏览器访问某个网址,mitmproxy 看到的效果是:

当前一共有136个请求,当前选择的是第16个请求,请求方法是 GET, 返回的状态码是200,代理的端口是8080,通过 J、K 键可上下切换到不同的请求,回车可以看到当前选中的请求详情,包括三部分,Request和Response还有 Detail
mitmproxy 快捷键
? 帮助文档 q 返回/退出程序 b 保存response body f 输入过滤条件 k 上 j 下 h 左 l 右 space 翻页 enter 进入接口详情 z 清屏 e 编辑 r 重新请求
HTTPS 抓包配置
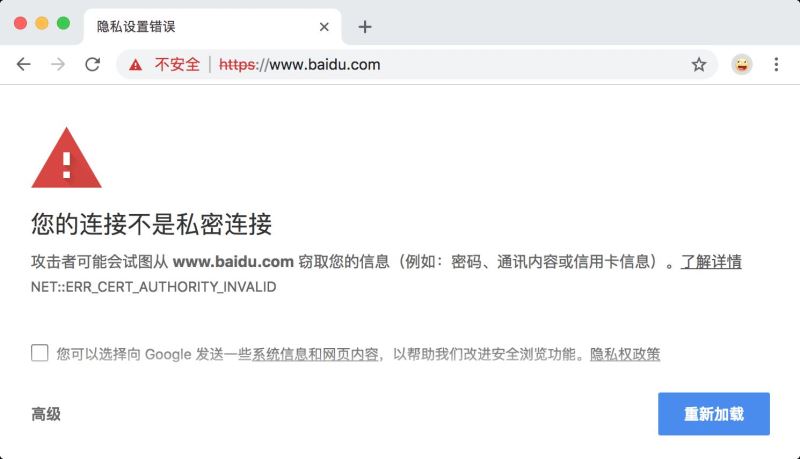
对于HTTPS请求,为了能正常抓到请求,需要先安装证书。没安装证书的请求看到的效果是这样的。
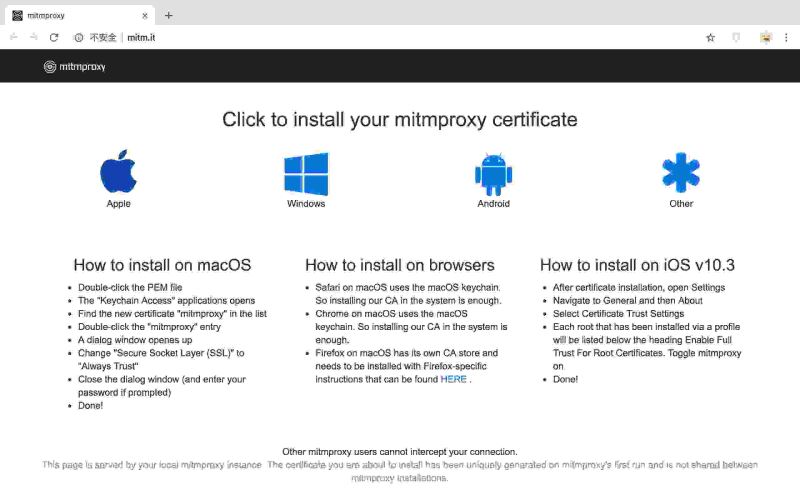
打开网址http://mitm.it , 选择匹配的平台,下载 HTTPS 证书。并按照对应的步骤进行安装
mitmweb
$ mitmweb
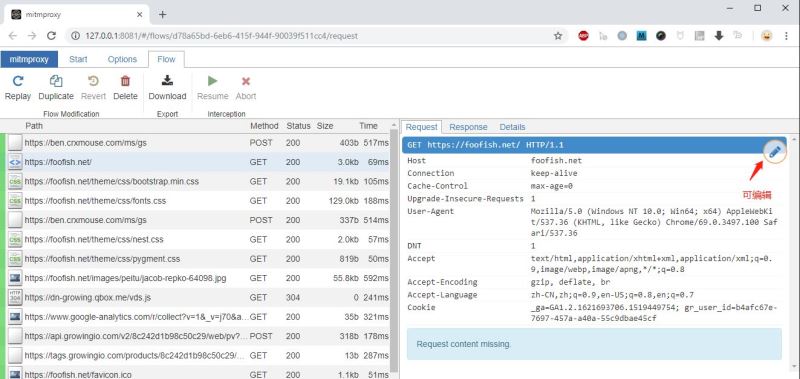
启动 mitmweb 命令后,会有一个类似Chrome开发者工具的Web页面,功能上类似mitmroxy,一样可以查看每个请求的详情,包括请求、响应,还可以对请求和响应内容进行修改,包括过滤、重新发送请求等常用功能。
mitmdump
$ mitmdump -s script.py
mitmdump 命令最大的特点就是可以自定义脚本,你可以在脚本中对请求或者响应内容通过编程的方式来控制,实现数据的解析、修改、存储等工作
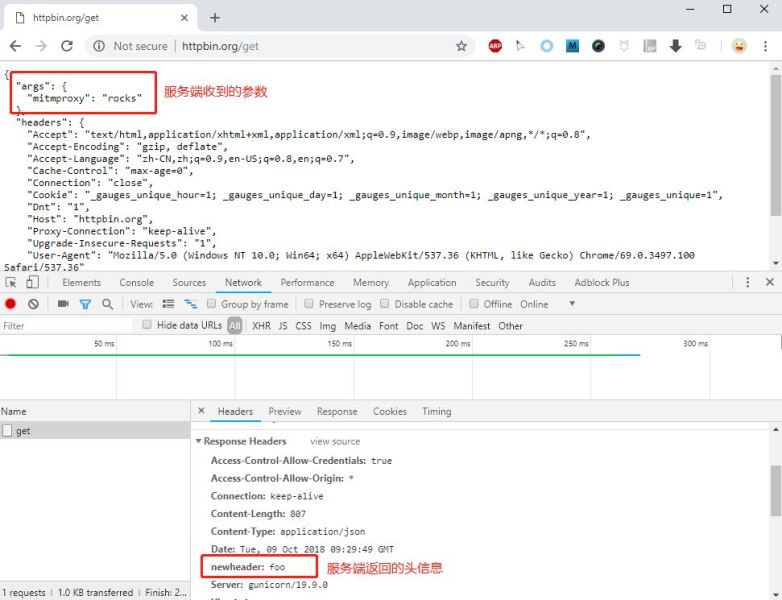
# script.py from mitmproxy import http def request(flow: http.HTTPFlow) -> None: # 将请求新增了一个查询参数 flow.request.query["mitmproxy"] = "rocks" def response(flow: http.HTTPFlow) -> None: # 将响应头中新增了一个自定义头字段 flow.response.headers["newheader"] = "foo" print(flow.response.text)
当你在浏览器请求http://httpbin.org/get ,看到的效果:
你还可以参考这些链接:
- 官方文档https://docs.mitmproxy.org/stable/
- GitHub地址https://github.com/mitmproxy/mitmproxy
- 更多脚本例子https://github.com/mitmproxy/mitmproxy/tree/master/examples/simple
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持码农之家。

















