给寻找编程代码教程的朋友们精选了Python相关的编程文章,网友扶博涛根据主题投稿了本篇教程内容,涉及到Python、雪花算法、snowflake、如何通过雪花算法用Python实现一个简单的发号器相关内容,已被108网友关注,相关难点技巧可以阅读下方的电子资料。
如何通过雪花算法用Python实现一个简单的发号器
实现一个简单的发号器
根据snowflake算法的原理实现一个简单的发号器,产生不重复、自增的id。
1.snowflake算法的简单描述
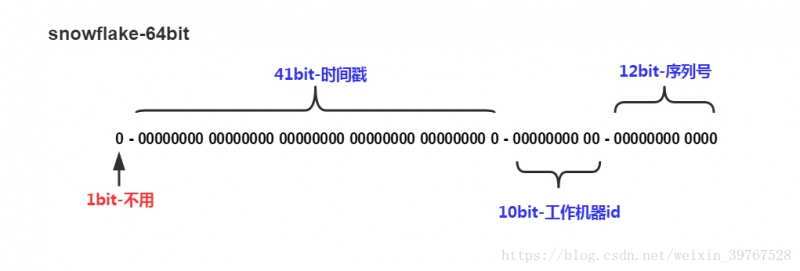
这里的snowflake算法是用二进制的,有64位。其中41位的时间戳表示:当前时间戳减去某个设定的起始时间,10位标识表示:不同的机器、数据库的标识ID等等,序列号为每秒或每毫秒内自增的id。
我做的时候没有用位运算去实现,而是做了一个十进制的,16位的(当时项目要求是16位的)。但是实现发号器的基本策略是一样的,通过时间戳和标识来防止重复,通过序列号实现自增。当然啦,重点不是发号器多少位,而是根据项目的实际情况,利用snowflake算法的原理,实现一个适合自己项目的发号器。
2.Python实现
时间戳:9位,起始时间为2018-01-01 00:00:00 ,时间戳为当前时间减去起始时间。时间戳有9为,可用时间为 999999999/(606024*365)≈31(年)。
标识ID:2位,我用的时候比较简单,只是涉及一个数据库的情况,所以用一张数据表对应一个标识ID,可用100张表。
序列号:5位,我时间戳用的是秒级的,但是5位是10万个序列号,经过测试在一秒内是完全够用的。
所以时间戳、标识ID、序列号的位数也没规定说一定要多少,根据自己项目的实际来即可。
代码如下:
import time
class MySnow:
def __init__(self,dataID):
self.start = int(time.mktime(time.strptime('2018-01-01 00:00:00', "%Y-%m-%d %H:%M:%S")))
self.last = int(time.time())
self.countID = 0
self.dataID = dataID # 数据ID,这个自定义或是映射
def get_id(self):
# 时间差部分
now = int(time.time())
temp = now-self.start
if len(str(temp)) < 9: # 时间差不够9位的在前面补0
length = len(str(temp))
s = "0" * (9-length)
temp = s + str(temp)
if now == self.last:
self.countID += 1 # 同一时间差,序列号自增
else:
self.countID = 0 # 不同时间差,序列号重新置为0
self.last = now
# 标识ID部分
if len(str(self.dataID)) < 2:
length = len(str(self.dataID))
s = "0" * (2-length)
self.dataID = s + str(self.dataID)
# 自增序列号部分
if self.countID == 99999: # 序列号自增5位满了,睡眠一秒钟
time.sleep(1)
countIDdata = str(self.countID)
if len(countIDdata) < 5: # 序列号不够5位的在前面补0
length = len(countIDdata)
s = "0"*(5-length)
countIDdata = s + countIDdata
id = str(temp) + str(self.dataID) + countIDdata
return id
使用方法:
snow = MySnow(dataID="00") print(snow.get_id())
其中dataID即为标识ID,countID为自增序列号。dataID可以一个通过自定义的映射表获得,这个视实际的项目情况而定。
3.关于并发
首先,直接用这个发号器是不能进行并发操作,会产生重复的id。如果真的要进行并发,那么就要权衡一下并发和位数的哪个更重要了!
拿实际例子来说吧,比如我并发的目的是为了节省时间,让程序更快的跑完,这时候为了并发,我把dataID中拿出一位来,标识不同的子进程,这样可以防止产生重复的id。但是实际上这用了位数去换取时间,如果是id位数比较少的情况,比如16位的,dataID比较少,我个人认为这样是不值得的,有些奢侈。这时候便是位数比并发重要啦。
当时如果位数充裕,比如20位的,需要并发就并发啦。
还有一种实现并发的方法,就是给发号器加锁,发号的时候加锁,发完了解锁。这个我没有试过,有兴趣的可以试一下哈哈。但是我有个疑惑啊,就是不断加锁和解锁切换,带来的时间和资源开销会不会很大呢。

















