给网友朋友们带来一篇相关的编程文章,网友慎湘灵根据主题投稿了本篇教程内容,涉及到python爬虫识别验证码、python爬虫怎么识别相关内容,已被489网友关注,内容中涉及的知识点可以在下方直接下载获取。
python爬虫怎么识别

1、输入式验证码
这种验证码主要是通过用户输入图片中的字母、数字、汉字等进行验证。如下图

解决思路:这种是最简单的一种,只要识别出里面的内容,然后填入到输入框中即可。这种识别技术叫OCR,这里我们推荐使用Python的第三方库,tesserocr。对于没有什么背影影响的验证码如图2,直接通过这个库来识别就可以。但是对于有嘈杂的背景的验证码这种,直接识别识别率会很低,遇到这种我们就得需要先处理一下图片,先对图片进行灰度化,然后再进行二值化,再去识别,这样识别率会大大提高。
2.滑动式验证码
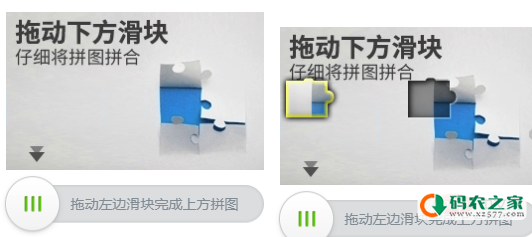
解决思路:对于这种验证码就比较复杂一点,但也是有相应的办法。我们直接想到的就是模拟人去拖动验证码的行为,点击按钮,然后看到了缺口的位置,最后把拼图拖到缺口位置处完成验证。
第一步:点击按钮。然后我们发现,在你没有点击按钮的时候那个缺口和拼图是没有出现的,点击后才出现,这为我们找到缺口的位置提供了灵感。
第二步:拖到缺口位置。我们知道拼图应该拖到缺口处,但是这个距离如果用数值来表示?通过我们第一步观察到的现象,我们可以找到缺口的位置。这里我们可以比较两张图的像素,设置一个基准值,如果某个位置的差值超过了基准值,那我们就找到了这两张图片不一样的位置,当然我们是从那块拼图的右侧开始并且从左到右,找到第一个不一样的位置时就结束,这是的位置应该是缺口的left,所以我们使用selenium拖到这个位置即可。这里还有个疑问就是如何能自动的保存这两张图?这里我们可以先找到这个标签,然后获取它的location和size,然后 top,bottom,left,right = location['y'] ,location['y']+size['height']+ location['x'] + size['width'] ,然后截图,最后抠图填入这四个位置就行。具体的使用可以查看selenium文档,点击按钮前抠张图,点击后再抠张图。最后拖动的时候要需要模拟人的行为,先加速然后减速。因为这种验证码有行为特征检测,人是不可能做到一直匀速的,否则它就判定为是机器在拖动,这样就无法通过验证了。
以上就是python爬虫怎么识别的详细内容,更多请关注码农之家其它相关文章!








