
插件介绍
Web Scraper是一款实用的浏览器插件,目前版本为1.72.7。作为一个Chrome爬虫插件,它提供了简单方便的方式来进行网页数据抓取。用户可以通过下载和安装Web Scraper插件,快速开始使用。使用说明清晰明了,即使对网络爬虫不熟悉的用户也可以轻松上手。该插件允许用户选择需要抓取的元素,并利用CSS选择器来定义提取规则。Web Scraper还可以模拟点击和滚动操作,以便抓取动态加载的内容。Web Scraper是一个功能强大且易于使用的浏览器插件,可以帮助用户快速方便地进行网页数据抓取。
这款Web Scraper插件就是这样一款你不需要写任何的代码,只需点击,点击,点击,四步使用者就能通过该插件来建立页面数据提取规则,从而快速对网页中需要的内容进行提取,最后还能把抓取的结果导出为Excel可以识别的CSV格式。
插件简介
作为小编,我们常常有种强烈的需求就是不需要编程,也能够网页抓取。做新媒体运营也是,很多时候会需要用到数据来帮助工作。比如,我们登陆淘宝,京东等商务网站,抓取某一类商品的规格说明,价格,厂家等信息;我们希望可以抓取我们进入头条上的最热门的文章,也可以抓取我们自己的所有文章列表,发布时间,阅读和浏览量等信息,当然也能抓取我们的粉丝列表。
在几分钟内开始网络抓取。 使用我们的免费 chrome 扩展程序或使用我们的 Cloud Scraper 自动执行任务。 无需下载软件,无需 Python/php/JS。
使用此扩展程序,您可以创建一个计划(站点地图)应该如何遍历网站以及应该提取什么内容。 使用这些站点地图,Web Scraper 将相应地导航站点并提取所有数据。 稍后可以将抓取的数据导出为 CSV。

特征
1. 抓取多个页面
2. 抓取的数据存放在本地存储
3. 多种数据选择类型
4. 从动态页面中提取数据(JavaScript+AJAX)
5.浏览抓取的数据
6. 将抓取的数据导出为 CSV
7. 导入、导出站点地图
8. 仅依赖于 Chrome 浏览器
插件使用说明
1、插件安装完成后,直接点击插件图标就可以直接使用,
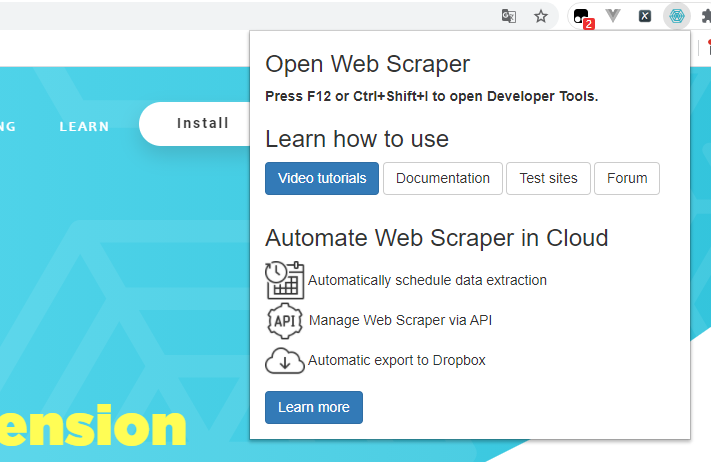
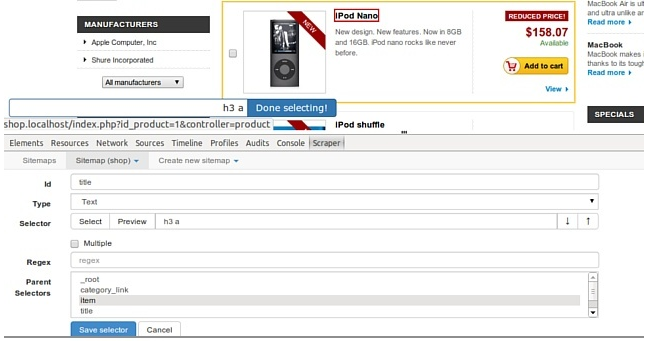
2、首先要使用该插件来提取网页数据需要在开发者工具模式中使用,使用快捷键Ctrl+Shift+I/F12或者点击右键,选择“检查(Inspect)”,在开发者工具下面就能看到WebScraper的Tab。
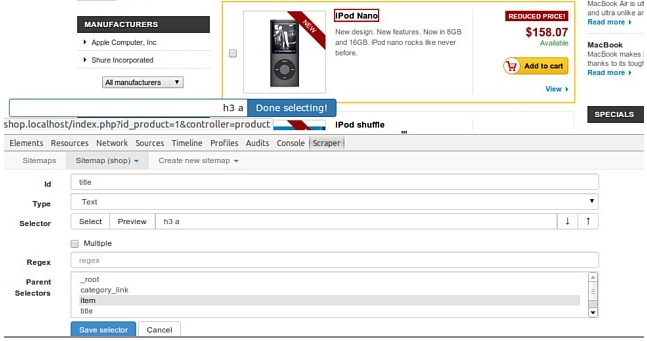
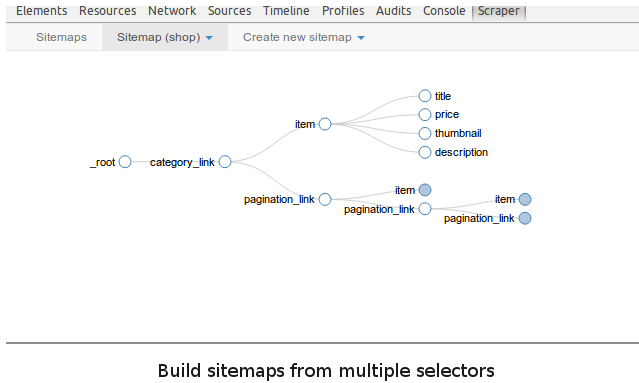
3、从多个选择器构建站点地图。

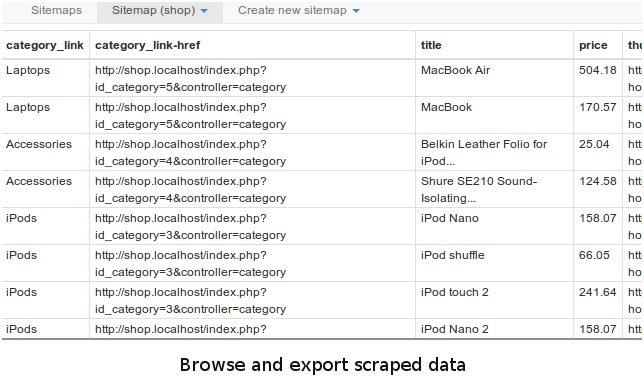
4、浏览并导出抓取的数据。

插件安装
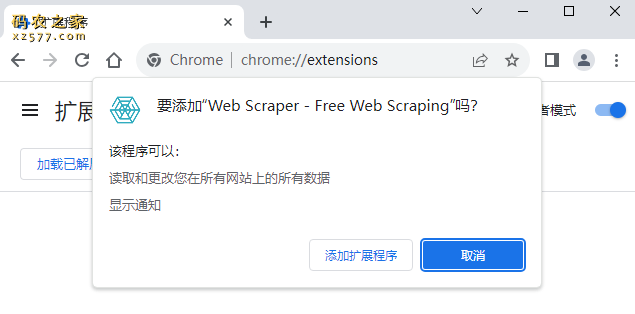
浏览器插件安装详细步骤:Chrome浏览器如何安装插件扩展
插件截图










试用了一段时间,还是或多或少有些bug,官网论坛里也有很多人讨论issue问题,总结:简单少量爬取,确实是方便快捷的利器,大数据量或复杂逻辑爬取,还是用python吧。