给大家整理一篇python爬虫实现天气预报相关的编程文章,网友许烨烁根据主题投稿了本篇教程内容,涉及到python、爬虫、天气预报、Python3爬虫教程之利用Python实现发送天气预报邮件相关内容,已被777网友关注,涉猎到的知识点内容可以在下方电子书获得。
Python3爬虫教程之利用Python实现发送天气预报邮件
前言
此次的目标是爬取指定城市的天气预报信息,然后再用Python发送邮件到指定的邮箱。
下面话不多说了,来一起看看详细的实现过程吧
一、爬取天气预报
1、首先是爬取天气预报的信息,用的网站是中国天气网,网址是http://www.weather.com.cn/static/html/weather.shtml,任意选择一个城市(比如武汉),然后要爬取的内容为下面的部分:

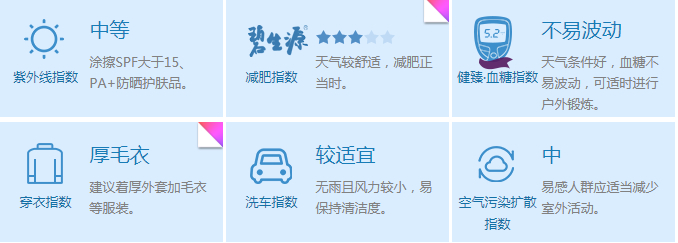
先查看网页源代码,并没有找到第一张图中的内容,说明是这些天气信息是通过别的方式加载出来的。我们打开开发者工具,点击XHR选项,发现没有任何内容,但是点击JS选项后可以找到如下内容:
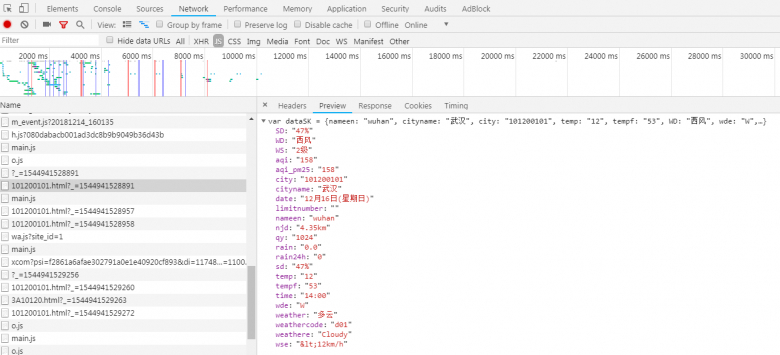
然后就是把URL复制下来进行爬取,不过要注意加上User-Agent和Referer字段,而且如果一直用一个User-Agent的话就会被识别出来,所以我们需要定义一个函数来返回随机的User-Agent以供使用。
def get_agent(): import random user_agent_list = [ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1" "Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6", "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1", "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5", "Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3", "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24", "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24" ] return random.choice(user_agent_list)
爬取后的结果如下:
{'PM2.5': '158',
'城市': '武汉',
'天气': '多云',
'日期': '12月16日(星期日)',
'洗车指数': '无雨且风力较小,易保持清洁度。',
'温度': '12℃',
'相对湿度': '47%',
'穿衣指数': '建议着厚外套加毛衣等服装。',
'紫外线指数': '涂擦SPF大于15、PA+防晒护肤品。',
'风力等级': '2级',
'风向': '西南风'}
2、我们已经能爬取天气预报的内容了,但是如果我们想要爬取任意城市的天气预报,又要怎么办呢?
先找几个城市对应的链接看一下:武汉(http://www.weather.com.cn/weather1d/101200101.shtml)、广州(http://www.weather.com.cn/weather/101280101.shtml?)、杭州(http://www.weather.com.cn/weather1d/101210101.shtml),很明显每个城市有一个对应的编码,而我们只要获得全国主要城市的编码信息,也就能得到这些城市的天气预报了。
这一步花费了我不少时间,问题就在于从哪里得到这些编码信息,最后找到了一个办法。首先是查看国内天气预报,当我们的鼠标移到某个省的地图上的时候,就会显示其省会的天气情况:
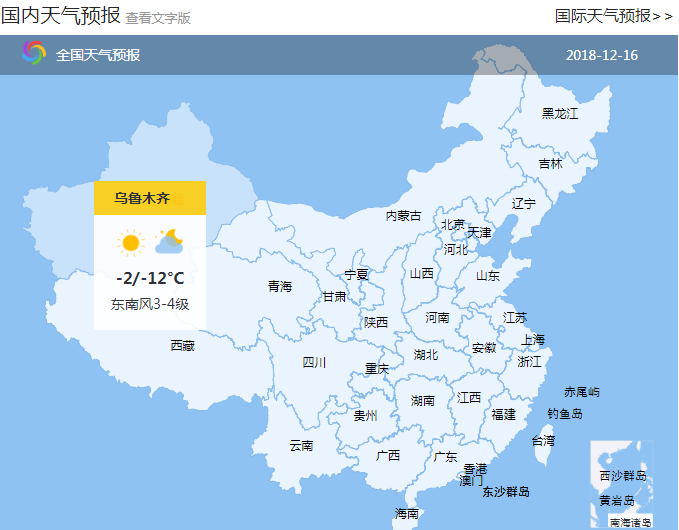
而当我们用鼠标左键点击的时候,就能够查看这个省的整体天气情况:
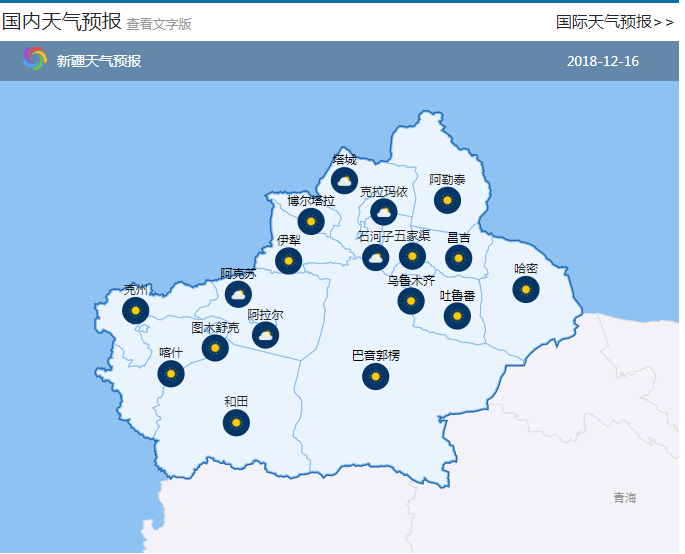
打开开发者工具,点击XHR选项,可以发现有如下内容,而这些数据里就包含着我们需要的编码信息:
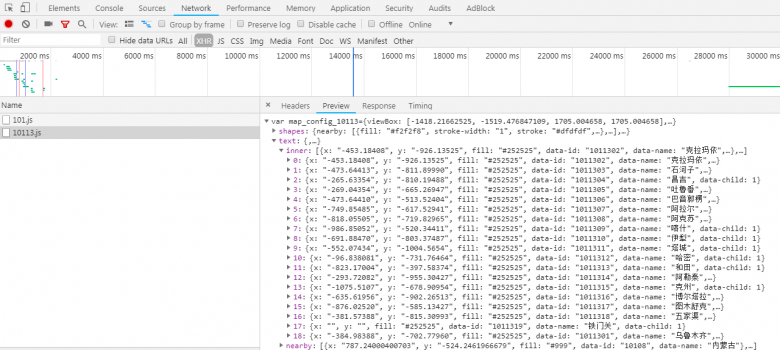
做到这一步我们就可以获得全国主要城市的编码信息了,不过要注意的是,这些编码并不都是能直接添加到我们的代码中进行使用的,通过观察可以发现,四个直辖市的编码是不需要做改变的,其余的省需要在得到的编码后面加上一个01。
二、发送邮件
要使用Python来发送邮件,需要使用两个模块:smtplib和email。这两个模块是Python自带的,只需import即可使用,其中smtplib模块主要负责发送邮件,email模块主要负责构造邮件。
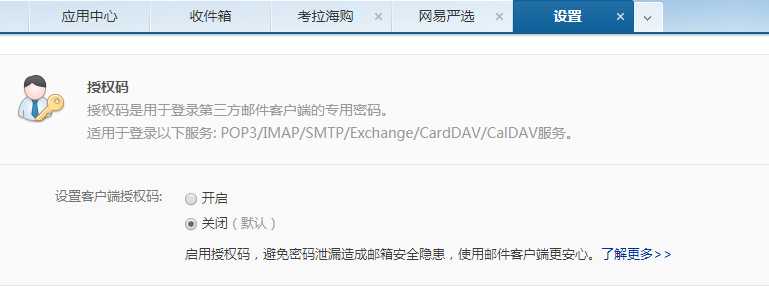
我使用的是163邮箱,用别的邮箱也可以,不过方法会有所不同。在发送邮件之前,需要先设置授权码,在设置完之后,要记住你的授权码,在后面会用到的:
一个测试的例子如下:
import smtplib
from email.header import Header
from email.mime.text import MIMEText
sender = "xxx@163.com" # 发件人的邮箱
password = "xxx" # 这里的密码不是登陆邮箱的密码,而是授权码
receiver = "xxx@163.com" # 收件人的邮箱,可以是同一个
mail = MIMEText("这是邮件内容", 'plain', 'utf-8') # 邮件内容
mail['Subject'] = Header('这是邮件主题', 'utf-8') # 邮件主题
mail['From'] = sender # 发件人
mail['To'] = receiver # 收件人
smtp = smtplib.SMTP()
smtp.connect('smtp.163.com', 25) # 连接邮箱服务器
smtp.login(sender, password) # 登录邮箱
smtp.sendmail(sender, receiver, mail.as_string()) # 第三个是把邮件内容变成字符串
smtp.quit() # 发送完毕,退出
print('邮件已成功发送!')
有几点要注意的是:
(1)mail['From']和mail['To']是一定要加上的,不能省略;
(2)由于使用的是163邮箱,所以连接服务器的时候使用的是smtp.163.com;
(3)邮件主题里不要使用“test”,不然会被标记为垃圾邮件。
三、运行结果
首先是程序运行的结果截图:
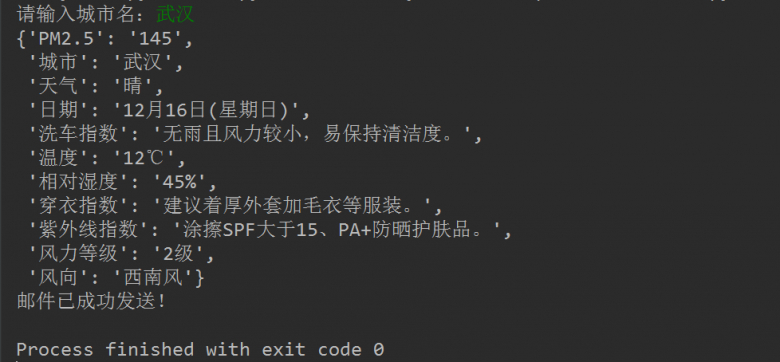
然后打开邮箱查看:

完整代码已上传到GitHub:https://github.com/QAQ112233/Weather(本地下载)
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,如果有疑问大家可以留言交流,谢谢大家对码农之家的支持。

















