为网友们分享了Python相关的编程文章,网友姜凯定根据主题投稿了本篇教程内容,涉及到Python、爬取数据、MySQL、Python爬取数据并写入MySQL数据库的实例相关内容,已被673网友关注,内容中涉及的知识点可以在下方直接下载获取。
Python爬取数据并写入MySQL数据库的实例
首先我们来爬取 http://html-color-codes.info/color-names/ 的一些数据。
按 F12 或 ctrl+u 审查元素,结果如下:
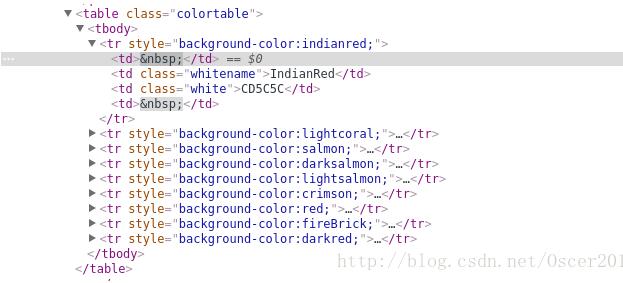
结构很清晰简单,我们就是要爬 tr 标签里面的 style 和 tr 下几个并列的 td 标签,下面是爬取的代码:
#!/usr/bin/env python
# coding=utf-8
import requests
from bs4 import BeautifulSoup
import MySQLdb
print('连接到mysql服务器...')
db = MySQLdb.connect("localhost","hp","Hp12345.","TESTDB")
print('连接上了!')
cursor = db.cursor()
cursor.execute("DROP TABLE IF EXISTS COLOR")
sql = """CREATE TABLE COLOR (
Color CHAR(20) NOT NULL,
Value CHAR(10),
Style CHAR(50) )"""
cursor.execute(sql)
hdrs = {'User-Agent':'Mozilla/5.0 (X11; Fedora; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko)'}
url = "http://html-color-codes.info/color-names/"
r = requests.get(url, headers = hdrs)
soup = BeautifulSoup(r.content.decode('gbk', 'ignore'), 'lxml')
trs = soup.find_all('tr') # 获取全部tr标签成为一个列表
for tr in trs: # 遍历列表里所有的tr标签单项
style = tr.get('style') # 获取每个tr标签里的属性style
tds = tr.find_all('td') # 将每个tr标签下的td标签获取为列表
td = [x for x in tds] # 获取的列表
name = td[1].text.strip() # 直接从列表里取值
hex = td[2].text.strip()
# print u'颜色: ' + name + u'颜色值: '+ hex + u'背景色样式: ' + style
# print 'color: ' + name + '\tvalue: '+ hex + '\tstyle: ' + style
insert_color = ("INSERT INTO COLOR(Color,Value,Style)" "VALUES(%s,%s,%s)")
data_color = (name, hex, style)
cursor.execute(insert_color, data_color)
db.commit()
# print '******完成此条插入!'
print '爬取数据并插入mysql数据库完成...'
运行结果:

$ mysql -u hp -p Enter password: Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 28 Server version: 5.7.17 MySQL Community Server (GPL) Copyright (c) 2000, 2011, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> use TESTDB Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A Database changed mysql> select * from COLOR; +----------------------+--------+----------------------------------------+ | Color | Value | Style | +----------------------+--------+----------------------------------------+ | IndianRed | CD5C5C | background-color:indianred; | | LightCoral | F08080 | background-color:lightcoral; | | Salmon | FA8072 | background-color:salmon; | | DarkSalmon | E9967A | background-color:darksalmon; | | LightSalmon | FFA07A | background-color:lightsalmon; | | Crimson | DC143C | background-color:crimson; | | Red | FF0000 | background-color:red; | | FireBrick | B22222 | background-color:fireBrick; | | DarkRed | 8B0000 | background-color:darkred; | | Pink | FFC0CB | background-color:pink; | | LightPink | FFB6C1 | background-color:lightpink; | | HotPink | FF69B4 | background-color:hotpink; | | DeepPink | FF1493 | background-color:deeppink; | ... | AntiqueWhite | FAEBD7 | background-color:antiquewhite; | | Linen | FAF0E6 | background-color:linen; | | LavenderBlush | FFF0F5 | background-color:lavenderblush; | | MistyRose | FFE4E1 | background-color:mistyrose; | | Gainsboro | DCDCDC | background-color:gainsboro; | | LightGrey | D3D3D3 | background-color:lightgrey; | | Silver | C0C0C0 | background-color:silver; | | DarkGray | A9A9A9 | background-color:darkgray; | | Gray | 808080 | background-color:gray; | | DimGray | 696969 | background-color:dimgray; | | LightSlateGray | 778899 | background-color:lightslategray; | | SlateGray | 708090 | background-color:slategray; | | DarkSlateGray | 2F4F4F | background-color:darkslategray; | | Black | 000000 | background-color:black; | +----------------------+--------+----------------------------------------+ 143 rows in set (0.00 sec)
以上这篇Python爬取数据并写入MySQL数据库的实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持码农之家。

















