为找教程的网友们整理了Python相关的编程文章,网友幸秀娟根据主题投稿了本篇教程内容,涉及到Python、模拟登陆、Python模拟微博登陆的方法介绍相关内容,已被822网友关注,如果对知识点想更进一步了解可以在下方电子资料中获取。
Python模拟微博登陆的方法介绍
本篇文章给大家带来的内容是关于Python模拟微博登陆的方法介绍(附代码),有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助。
今天想做一个微博爬个人页面的工具,满足一些不可告人的秘密。那么首先就要做那件必做之事!模拟登陆……
我对代码进行了优化,重构成了Python 3.6 版本,并且加入了大量注释方便大家学习。
PC 登录新浪微博时, 在客户端用js预先对用户名、密码都进行了加密, 而且在POST之前会GET 一组参数,这也将作为POST_DATA 的一部分。 这样, 就不能用通常的那种简单方法来模拟POST 登录( 比如 人人网 )。
1、在提交POST请求之前, 需要GET 获取两个参数。
地址是:
http://login.sina.com.cn/sso/login.php?client=ssologin.js(v1.3.18)
得到的数据中有 servertime 和 nonce 的值, 是随机的,其他值貌似没什么用。
def get_servertime():
url = 'http://login.sina.com.cn/sso/prelogin.php?entry=weibo&callback=sinaSSOController.preloginCallBack&su=dW5kZWZpbmVk&client=ssologin.js(v1.3.18)&_=1329806375939'
# 返回出来的是一个Response对象,无法直接获取,text后,可以通过正则匹配到
# 大概长这样子的:sinaSSOController.preloginCallBack({"retcode":0,"servertime":1545606770, ...})
data = requests.request('GET', url).text
p = re.compile('\((.*)\)')
try:
json_data = p.search(data).group(1)
data = json.loads(json_data)
servertime = str(data['servertime'])
nonce = data['nonce']
return servertime, nonce
except:
print('获取 severtime 失败!')
return None
2、通过httpfox 观察POST 的数据, 参数较复杂,其中 “su" 是加密后的username, sp 是加密后的password。servertime 和 nonce 是上一步得到的。其他参数是不变的。
username 经过了BASE64 计算:
username = base64.encodestring( urllib.quote(username) )[:-1]
password 经过了三次SHA1 加密, 且其中加入了 servertime 和 nonce 的值来干扰。
即: 两次SHA1加密后, 将结果加上 servertime 和 nonce 的值, 再SHA1 算一次。
def get_pwd(pwd, servertime, nonce): # 第一次计算,注意Python3 的加密需要encode,使用bytes pwd1 = hashlib.sha1(pwd.encode()).hexdigest() # 使用pwd1的结果在计算第二次 pwd2 = hashlib.sha1(pwd1.encode()).hexdigest() # 使用第二次的结果再加上之前计算好的servertime和nonce值,hash一次 pwd3_ = pwd2 + servertime + nonce pwd3 = hashlib.sha1(pwd3_.encode()).hexdigest() return pwd3 def get_user(username): # 将@符号转换成url中能够识别的字符 _username = urllib.request.quote(username) # Python3中的base64计算也是要字节 # base64出来后,最后有一个换行符,所以用了切片去了最后一个字符 username = base64.encodebytes(_username.encode())[:-1] return username
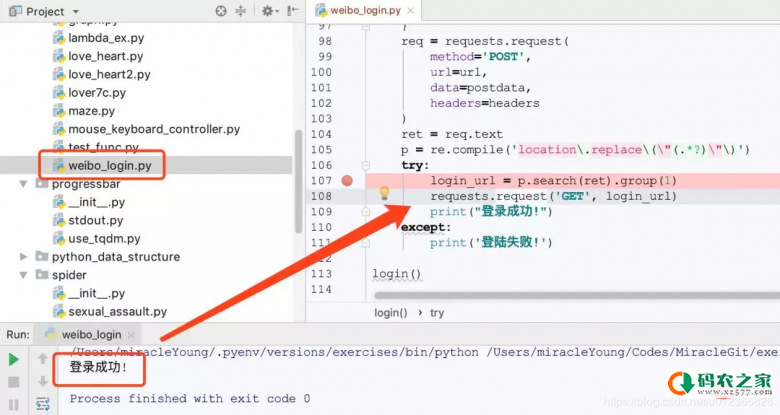
3、将参数组织好, POST请求。 这之后还没有登录成功。
POST后得到的内容中包含一句:
location.replace("http://weibo.com/ajaxlogin.php?framelogin=1&callback=parent.sinaSSOController.feedBackUrlCallBack&retcode=101&reason=%B5%C7%C2%BC%C3%FB%BB%F2%C3%DC%C2%EB%B4%ED%CE%F3")
这是登录失败时的结果, 登录成功后结果与之类似, 不过retcode 的值是0 。
接下来再请求这个URL,这样就成功登录到微博了。
记得要提前build 缓存。
以上就是Python模拟微博登陆的方法介绍(附代码)的详细内容,更多请关注码农之家其它相关文章!

















