本站精选了一篇python3相关的编程文章,网友靳晨辰根据主题投稿了本篇教程内容,涉及到python3、urllib、urlopen、解决python3 urllib中urlopen报错的问题相关内容,已被291网友关注,内容中涉及的知识点可以在下方直接下载获取。
解决python3 urllib中urlopen报错的问题
前言
最近更新了Python版本,准备写个爬虫,意外的发现urllib库中属性不存在urlopen,于是各种google,然后总结一下给出解决方案
问题的出现
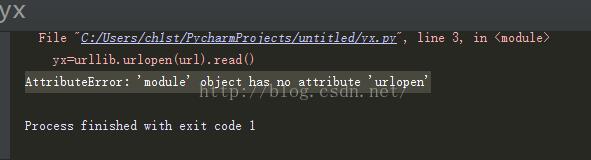
AttributeError: 'module' object has no attribute 'urlopen'
问题的解决途径
我们先来看下官方文档的解释:
a new urllib package was created. It consists of code from urllib, urllib2, urlparse, and robotparser. The old modules have all been removed. The new package has five submodules: urllib.parse, urllib.request, urllib.response, urllib.error, and urllib.robotparser. The urllib.request.urlopen() function uses the url opener from urllib2. (Note that the unittests have not been renamed for the beta, but they will be renamed in the future.)
也就是说官方3.0版本已经把urllib2,urlparse等五个模块都并入了urllib中,也就是整合了。
正确的使用方法
import urllib.request url="http://www.baidu.com" get=urllib.request.urlopen(url).read() print(get)
结果示意图:
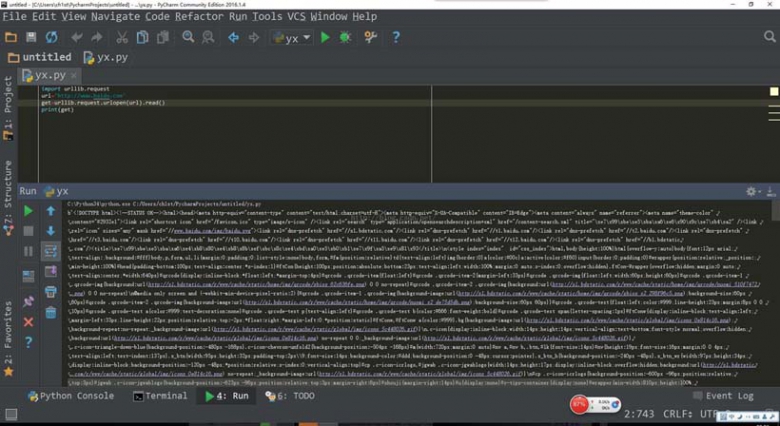
其实也是可以换个utf-8的编码让读取出来的源码更正确的,但这已经是番外的不再提了。
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作能带来一定的帮助,如果有疑问大家可以留言交流,谢谢大家对码农之家的支持。

















