给网友朋友们带来一篇python八大排序算法相关的编程文章,网友厉康复根据主题投稿了本篇教程内容,涉及到八大排序、八大排序算法、python、python八大排序算法速度实例对比相关内容,已被792网友关注,下面的电子资料对本篇知识点有更加详尽的解释。
python八大排序算法速度实例对比
这篇文章并不是介绍排序算法原理的,纯粹是想比较一下各种排序算法在真实场景下的运行速度。
算法由 Python 实现,可能会和其他语言有些区别,仅当参考就好。
测试的数据是自动生成的,以数组形式保存到文件中,保证数据源的一致性。
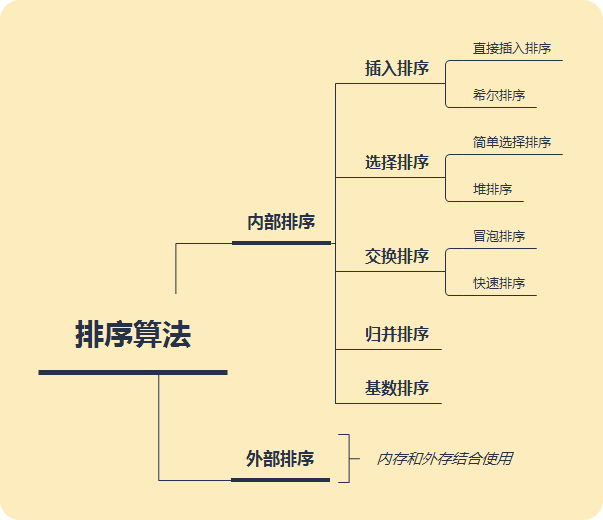
排序算法
直接插入排序
时间复杂度:O(n²)
空间复杂度:O(1)
稳定性:稳定
def insert_sort(array):
for i in range(len(array)):
for j in range(i):
if array[i] < array[j]:
array.insert(j, array.pop(i))
break
return array
希尔排序
时间复杂度:O(n)
空间复杂度:O(n√n)
稳定性:不稳定
def shell_sort(array):
gap = len(array)
while gap > 1:
gap = gap // 2
for i in range(gap, len(array)):
for j in range(i % gap, i, gap):
if array[i] < array[j]:
array[i], array[j] = array[j], array[i]
return array
简单选择排序
时间复杂度:O(n²)
空间复杂度:O(1)
稳定性:不稳定
def select_sort(array):
for i in range(len(array)):
x = i # min index
for j in range(i, len(array)):
if array[j] < array[x]:
x = j
array[i], array[x] = array[x], array[i]
return array
堆排序
时间复杂度:O(nlog₂n)
空间复杂度:O(1)
稳定性:不稳定
def heap_sort(array):
def heap_adjust(parent):
child = 2 * parent + 1 # left child
while child < len(heap):
if child + 1 < len(heap):
if heap[child + 1] > heap[child]:
child += 1 # right child
if heap[parent] >= heap[child]:
break
heap[parent], heap[child] = \
heap[child], heap[parent]
parent, child = child, 2 * child + 1
heap, array = array.copy(), []
for i in range(len(heap) // 2, -1, -1):
heap_adjust(i)
while len(heap) != 0:
heap[0], heap[-1] = heap[-1], heap[0]
array.insert(0, heap.pop())
heap_adjust(0)
return array
冒泡排序
时间复杂度:O(n²)
空间复杂度:O(1)
稳定性:稳定
def bubble_sort(array):
for i in range(len(array)):
for j in range(i, len(array)):
if array[i] > array[j]:
array[i], array[j] = array[j], array[i]
return array
快速排序
时间复杂度:O(nlog₂n)
空间复杂度:O(nlog₂n)
稳定性:不稳定
def quick_sort(array):
def recursive(begin, end):
if begin > end:
return
l, r = begin, end
pivot = array[l]
while l < r:
while l < r and array[r] > pivot:
r -= 1
while l < r and array[l] <= pivot:
l += 1
array[l], array[r] = array[r], array[l]
array[l], array[begin] = pivot, array[l]
recursive(begin, l - 1)
recursive(r + 1, end)
recursive(0, len(array) - 1)
return array
归并排序
时间复杂度:O(nlog₂n)
空间复杂度:O(1)
稳定性:稳定
def merge_sort(array):
def merge_arr(arr_l, arr_r):
array = []
while len(arr_l) and len(arr_r):
if arr_l[0] <= arr_r[0]:
array.append(arr_l.pop(0))
elif arr_l[0] > arr_r[0]:
array.append(arr_r.pop(0))
if len(arr_l) != 0:
array += arr_l
elif len(arr_r) != 0:
array += arr_r
return array
def recursive(array):
if len(array) == 1:
return array
mid = len(array) // 2
arr_l = recursive(array[:mid])
arr_r = recursive(array[mid:])
return merge_arr(arr_l, arr_r)
return recursive(array)
基数排序
时间复杂度:O(d(r+n))
空间复杂度:O(rd+n)
稳定性:稳定
def radix_sort(array):
bucket, digit = [[]], 0
while len(bucket[0]) != len(array):
bucket = [[], [], [], [], [], [], [], [], [], []]
for i in range(len(array)):
num = (array[i] // 10 ** digit) % 10
bucket[num].append(array[i])
array.clear()
for i in range(len(bucket)):
array += bucket[i]
digit += 1
return array
速度比较
from random import random
from json import dumps, loads
# 生成随机数文件
def dump_random_array(file='numbers.json', size=10 ** 4):
fo = open(file, 'w', 1024)
numlst = list()
for i in range(size):
numlst.append(int(random() * 10 ** 10))
fo.write(dumps(numlst))
fo.close()
# 加载随机数列表
def load_random_array(file='numbers.json'):
fo = open(file, 'r', 1024)
try:
numlst = fo.read()
finally:
fo.close()
return loads(numlst)
from _datetime import datetime
# 显示函数执行时间
def exectime(func):
def inner(*args, **kwargs):
begin = datetime.now()
result = func(*args, **kwargs)
end = datetime.now()
inter = end - begin
print('E-time:{0}.{1}'.format(
inter.seconds,
inter.microseconds
))
return result
return inner
如果数据量特别大,采用分治算法的快速排序和归并排序,可能会出现递归层次超出限制的错误。
解决办法:导入 sys 模块(import sys),设置最大递归次数(sys.setrecursionlimit(10 ** 8))。
@exectime
def bubble_sort(array):
for i in range(len(array)):
for j in range(i, len(array)):
if array[i] > array[j]:
array[i], array[j] = array[j], array[i]
return array
array = load_random_array()
print(bubble_sort(array) == sorted(array))
↑ 示例:测试直接插入排序算法的运行时间,@exectime 为执行时间装饰器。
算法执行时间
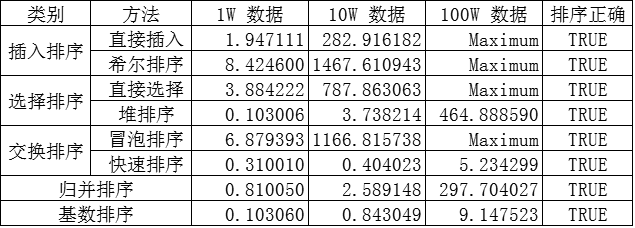
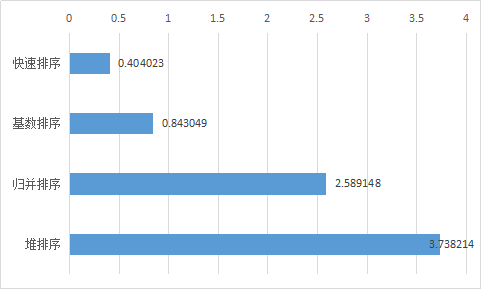
算法速度比较

总结
以上就是本文关于Python八大排序算法速度实例对比的全部内容,希望对大家有所帮助。感兴趣的朋友可以继续参阅本站:
Python3简单实例计算同花的概率代码
Python语言描述最大连续子序列和
Python实现调度算法代码详解
如有不足之处,欢迎留言指出。感谢朋友们对本站的支持!

















