给网友朋友们带来一篇相关的编程文章,网友詹琬莹根据主题投稿了本篇教程内容,涉及到Pandas筛选某列过滤、Pandas列过滤、Pandas筛选某列过滤相关内容,已被672网友关注,下面的电子资料对本篇知识点有更加详尽的解释。
Pandas筛选某列过滤
通过dataframe的第二个条件,进行筛选
#make字段异常值清洗 new = data[['make', 'model', 'instance_id']] new['make_model'] = new['make']+':::'+new['model'] new.head(3)

# new.make_model.value_counts() # 统计make_model列属性值出现的次数 new.make_model.value_counts()[new.make_model.value_counts() <= 200] """ OPPO:::OPPO+A59st 200 OPPO:::3007 200 Xiaomi:::Redmi%20Note%203 200 Meizu:::MEIZU-M6 199 samsung:::SM-N9006 199 ... OPPO,OPPO A53,A53:::OPPO A53 1 boway U15:::boway U15 1 BaiMao:::BM I8 1 vivo:::vivoy75a 1 SUPERJO:::SUPERJO 1 Name: make_model, Length: 15597, dtype: int64 """
找出符合第二列筛选条件的index(这里index不是0-n,而是刚才value_counts()的index)
(new.make_model.value_counts()[new.make_model.value_counts() <= 200]).index
"""
Index(['OPPO:::OPPO+A59st', 'OPPO:::3007', 'Xiaomi:::Redmi%20Note%203',
'Meizu:::MEIZU-M6', 'samsung:::SM-N9006', 'Coolpad:::MTS-T0',
'OPPO R11st:::OPPO R11st', 'Blephone:::lephone T7A', 'GIONEE:::GN9011',
'Meizu:::PRO 7-S',
...
'HUAWEI:::HUAWEI%25252BG7-UL20', 'VOLTE:::L3', 'GIONEE:::GN868',
'alps:::SOP-i9', 'GT-I9300I:::GT-I9300I',
'OPPO,OPPO A53,A53:::OPPO A53', 'boway U15:::boway U15',
'BaiMao:::BM I8', 'vivo:::vivoy75a', 'SUPERJO:::SUPERJO'],
dtype='object', length=15597)
"""
new.make_model
"""
0 HUAWEI:::HUAWEI-CAZ-AL10
1 Xiaomi:::Redmi Note 4
2 OPPO:::OPPO+R11s
3 NaN
4 Apple:::iPhone 7
...
1041669 OPPO:::OPPO-R9s
1041670 Xiaomi:::MI-5X
1041671 vivo:::vivo Y37
1041672 vivo:::vivo%20Y75A
1041673 OPPO:::A31
Name: make_model, Length: 1041674, dtype: object
"""dataframe.loc(行索引, 列名)
# 在make_model列, # 定位符合 new.make_model.isin((new.make_model.value_counts()[new.make_model.value_counts() <= 200]).index) 的行 # new.loc[new.make_model.isin((new.make_model.value_counts()[new.make_model.value_counts() <= 200]).index), 'make_model'] = 'other' #去除低频词
再感受下第二个case
data['day'] = data['time'].apply(lambda x : int(time.strftime("%d", time.localtime(x))))
data['period'] = data['day']
data[['period']].head(3)
data['period'].unique() # array([29, 30, 31, 27, 1, 2, 28, 3])
直接用列筛选
[data['period']<27]
"""
[0 False
1 False
2 False
3 False
4 False
...
1041669 True
1041670 True
1041671 True
1041672 True
1041673 True
Name: period, Length: 1041674, dtype: bool]
"""
data['period']<27
"""
0 False
1 False
2 False
3 False
4 False
...
1041669 True
1041670 True
1041671 True
1041672 True
1041673 True
Name: period, Length: 1041674, dtype: bool
"""挑选period列,值<27的行(已成功挑选)
data['period'][data['period']<27]
"""
950 1
951 1
952 1
953 1
954 1
..
1041669 3
1041670 3
1041671 3
1041672 3
1041673 3
Name: period, Length: 348536, dtype: int64
"""
data['period'][data['period']<27] = data['period'][data['period']<27] + 31这样可以使用head展示
data[['period']][data['period']<27].head(3)

还有种单列就能筛选的方法
t2['receive_number'] = t2.date_received.apply(lambda s:len(s.split(':')))
t2 = t2[t2.receive_number>1]
t2.head(3)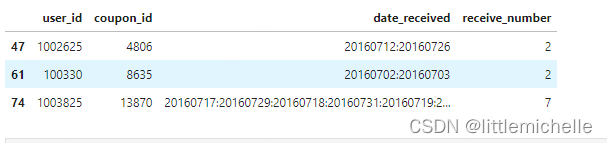
到此这篇关于Pandas筛选某列过滤的方法的文章就介绍到这了,更多相关Pandas筛选某列过滤内容请搜索码农之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持码农之家!








