本站收集了一篇相关的编程文章,网友卓彩萱根据主题投稿了本篇教程内容,涉及到python re.match、python re.match相关内容,已被831网友关注,涉猎到的知识点内容可以在下方电子书获得。
python re.match
1 re.match 说明
re.match() 从开始位置开始往后查找,返回第一个符合规则的对象,如果开始位置不符合匹配队形则返回None
从源码里面看下match 里面的内容

里面有3个参数 pattern ,string ,flags
pattern : 是匹配的规则内容
string : 要匹配的字符串
flag : 标志位(这个是可选的,可写,可不写),用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等
下面写一个demo
str_content = "Python is a good language" # 要匹配的内容, 对应match 里面的string
str_pattern = "Python" # pattern 匹配的规则
re_content = re.match("Python", str_content)
print(re_content)打印的结果如下

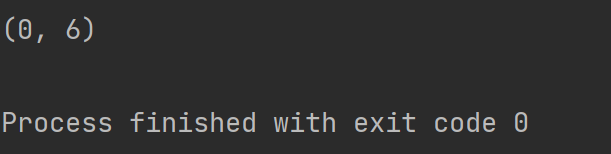
可以看到匹配的的下标是(0,6) 匹配的内容是Python
2 span 的使用
如果想获取匹配的下标,可以使用span ,
match span 的作用就是返回匹配到内容的下标
使用方式如下
import re # 导入re 模块
str_content = "Python is a good language" # 要匹配的内容, 对应match 里面的string
str_pattern = "Python" # pattern 匹配的规则
re_content = re.match("Python", str_content).span()
print(re_content)打印结果如下
3 group 的使用
如果想获取匹配到结果的内容可以使用group ,注意使用group的时候就不要在使用span 了
import re # 导入re 模块
str_content = "Python is a good language" # 要匹配的内容, 对应match 里面的string
str_pattern = "Python" # pattern 匹配的规则
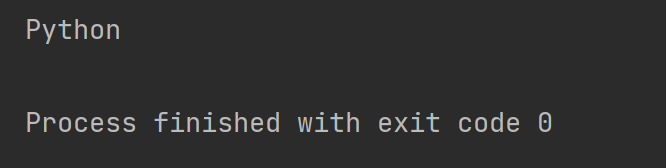
re_content = re.match("Python", str_content)
print(re_content.group())打印结果如下
4 匹配不到内容的情况
如下面的返回结果为None
import re # 导入re 模块
str_content = "Python is a good language" # 要匹配的内容, 对应match 里面的string
str_pattern = "Python" # pattern 匹配的规则
re_content = re.match("python", str_content)
print(re_content)
# 或者
str_content = "Python is a good language" # 要匹配的内容, 对应match 里面的string
str_pattern = "Python" # pattern 匹配的规则
re_content = re.match("is", str_content)
print(re_content)5 使用group 注意点
注意当匹配不到内容的时候就使用group 或者span 的时候会报错,所以当使用group 的时候 先判断下是否匹配到内容然后在使用它
例如匹配不到内容的情况下使用group
import re # 导入re 模块
str_content = "Python is a good language" # 要匹配的内容, 对应match 里面的string
str_pattern = "Python" # patterPn 匹配的规则
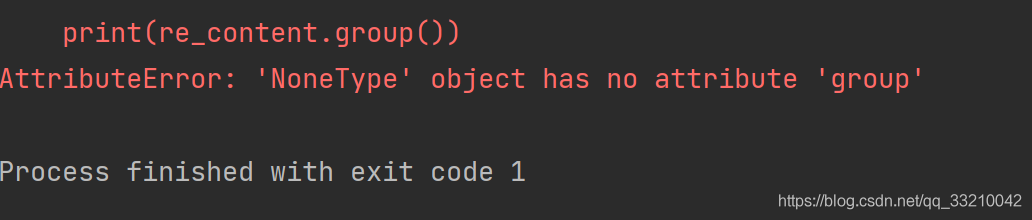
re_content = re.match("python", str_content)
print(re_content.group())这样会报错,报错内容如下
添加是否匹配判断
import re # 导入re 模块
str_content = "Python is a good language" # 要匹配的内容, 对应match 里面的string
str_pattern = "Python" # patterPn 匹配的规则
re_content = re.match("python", str_content)
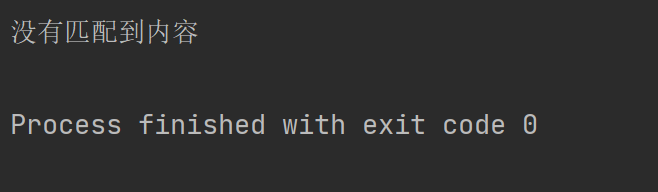
if re_content:
print(re_content.group())
else:
print("没有匹配到内容")打印结果如下
这样会走到else 里面就不会报错了
6 flag 的使用
写一个忽略大小写的情况
import re # 导入re 模块
str_content = "Python is a good language" # 要匹配的内容, 对应match 里面的string
str_pattern = "Python" # patterPn 匹配的规则
re_content = re.match("python", str_content, re.I)
if re_content:
print(re_content.group())
else:
print("没有匹配到内容")打印结果如下:
flags : 可选,表示匹配模式,比如忽略大小写,多行模式等,具体参数为:
- re.I 忽略大小写
- re.L 表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境
- re.M 多行模式
- re.S 即为 . 并且包括换行符在内的任意字符(. 不包括换行符)
- re.U 表示特殊字符集 \w, \W, \b, \B, \d, \D, \s, \S 依赖于 Unicode 字符属性数据库
- re.X 为了增加可读性,忽略空格和 # 后面的注释
到此这篇关于python re.match函数的具体使用的文章就介绍到这了,更多相关python re.match内容请搜索码农之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持码农之家!








