给网友们整理相关的编程文章,网友崔涵映根据主题投稿了本篇教程内容,涉及到spark编程、python实例、spark编程python实例、spark编程python实例相关内容,已被545网友关注,涉猎到的知识点内容可以在下方电子书获得。
spark编程python实例
spark编程python实例
ValueError: Cannot run multiple SparkContexts at once; existing SparkContext(app=PySparkShell, master=local[])
1.pyspark在jupyter notebook中开发,测试,提交
1.1.启动
IPYTHON_OPTS="notebook" /opt/spark/bin/pyspark

下载应用,将应用下载为.py文件(默认notebook后缀是.ipynb)
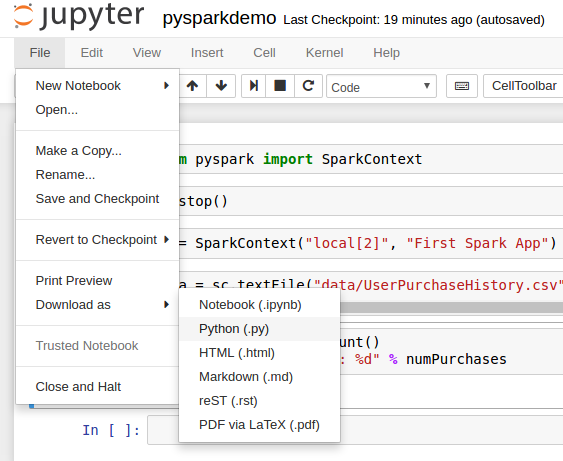
2.在shell中提交应用
wxl@wxl-pc:/opt/spark/bin$ spark-submit /bin/spark-submit /home/wxl/Downloads/pysparkdemo.py
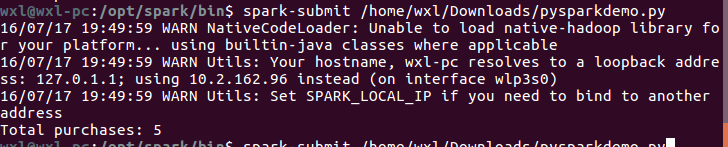
3.遇到的错误及解决
ValueError: Cannot run multiple SparkContexts at once; existing SparkContext(app=PySparkShell, master=local[*])
d*
3.1.错误
ValueError: Cannot run multiple SparkContexts at once; existing SparkContext(app=PySparkShell, master=local[*])
d*
ValueError: Cannot run multiple SparkContexts at once; existing SparkContext(app=PySparkShell, master=local[*]) created byat /usr/local/lib/python2.7/dist-packages/IPython/utils/py3compat.py:288
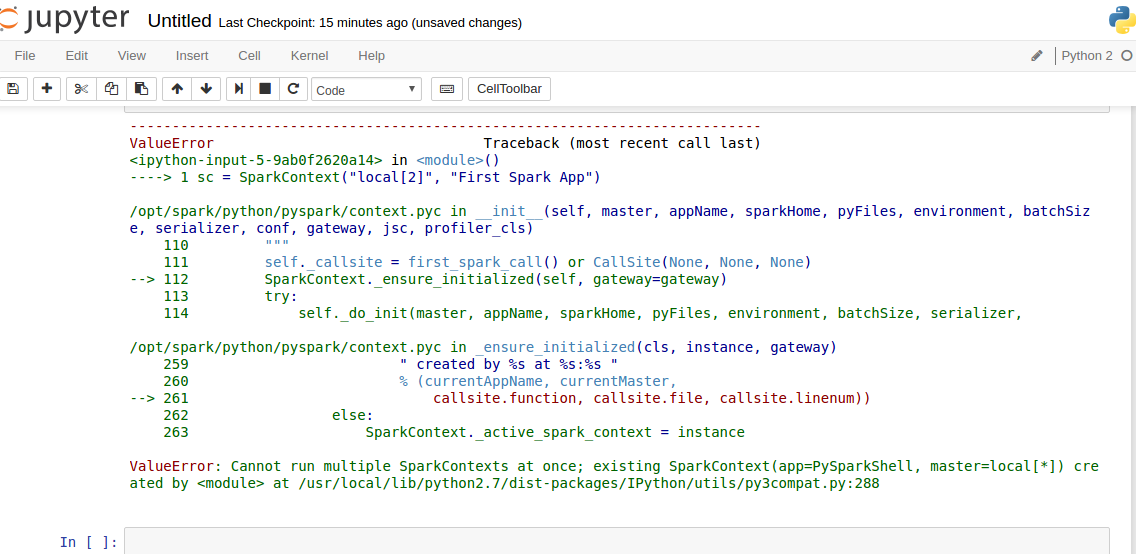
3.2.解决,成功运行
在from之后添加
try:
sc.stop()
except:
pass
sc=SparkContext('local[2]','First Spark App')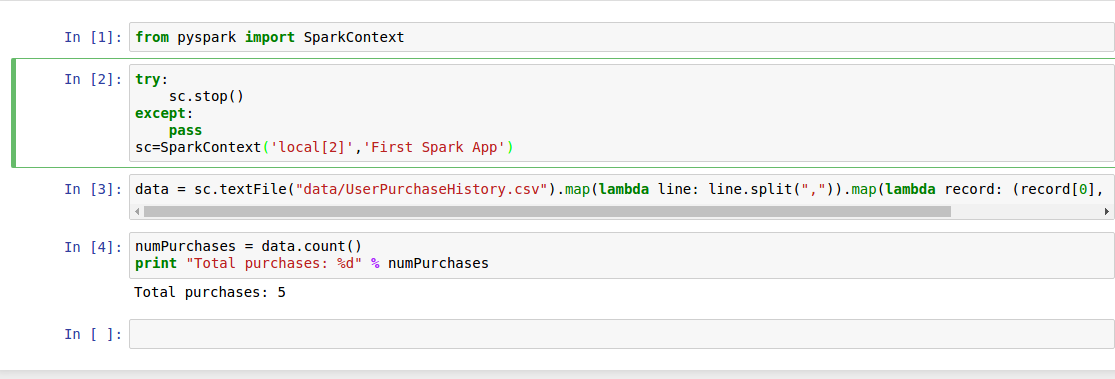
4.源码
pysparkdemo.ipynb
{
"cells": [
{
"cell_type": "code",
"execution_count": 1,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"from pyspark import SparkContext"
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"try:\n",
" sc.stop()\n",
"except:\n",
" pass\n",
"sc=SparkContext('local[2]','First Spark App')"
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"data = sc.textFile(\"data/UserPurchaseHistory.csv\").map(lambda line: line.split(\",\")).map(lambda record: (record[0], record[1], record[2]))"
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {
"collapsed": false,
"scrolled": true
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Total purchases: 5\n"
]
}
],
"source": [
"numPurchases = data.count()\n",
"print \"Total purchases: %d\" % numPurchases"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": []
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 2",
"language": "python",
"name": "python2"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 2
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython2",
"version": "2.7.12"
}
},
"nbformat": 4,
"nbformat_minor": 0
}pysparkdemo.py
# coding: utf-8
# In[1]:
from pyspark import SparkContext
# In[2]:
try:
sc.stop()
except:
pass
sc=SparkContext('local[2]','First Spark App')
# In[3]:
data = sc.textFile("data/UserPurchaseHistory.csv").map(lambda line: line.split(",")).map(lambda record: (record[0], record[1], record[2]))
# In[4]:
numPurchases = data.count()
print "Total purchases: %d" % numPurchases
# In[ ]:
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持码农之家。









