给网友朋友们带来一篇相关的编程文章,网友越乐心根据主题投稿了本篇教程内容,涉及到Pandas库作用、10分钟入门Pandas、pandas常见使用、Pandas库作用相关内容,已被936网友关注,内容中涉及的知识点可以在下方直接下载获取。
Pandas库作用
Pandas的介绍
pandas 是基于NumPy 的一种工具,该工具是为解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。你很快就会发现,它是使Python成为强大而高效的数据分析环境的重要因素之一。
- 2008年WesMcKinney开发出的库
- 专门用于数据挖掘的开源python库
- 以Numpy为基础,借力Numpy模块在计算方面性能高的优势
- 基于matplotlib,能够简便的画图
- 独特的数据结构
数据处理的时候经常性需要整理出表格,在这里介绍pandas常见使用:
参考链接:10 minutes to pandas https://pandas.pydata.org/docs/user_guide/10min.html#min
数据结构
Pandas常见的就两种数据类型:Series和DataFrame,可以对应理解为向量和矩阵,前者是一维的,后者是二维的。在DF中类似统计学中的数据组织方式,一行代表一项数据,一列代表一种特征,用这种方式记忆能够帮你更好理解DF。需要注意的是:在DF中index是行,column是列。


导入导出数据
常使用.csv格式的文件,我们在导入数据的时候使用pd.read_csv(),在导出数据的时候用df.write_csv(“/data/ymz.csv”).
# 读入数据
In [144]: pd.read_csv("foo.csv")
Out[144]:
Unnamed: 0 A B C D
0 2000-01-01 0.350262 0.843315 1.798556 0.782234
1 2000-01-02 -0.586873 0.034907 1.923792 -0.562651
2 2000-01-03 -1.245477 -0.963406 2.269575 -1.612566
3 2000-01-04 -0.252830 -0.498066 3.176886 -1.275581
4 2000-01-05 -1.044057 0.118042 2.768571 0.386039
.. ... ... ... ... ...
995 2002-09-22 -48.017654 31.474551 69.146374 -47.541670
996 2002-09-23 -47.207912 32.627390 68.505254 -48.828331
997 2002-09-24 -48.907133 31.990402 67.310924 -49.391051
998 2002-09-25 -50.146062 33.716770 67.717434 -49.037577
999 2002-09-26 -49.724318 33.479952 68.108014 -48.822030
[1000 rows x 5 columns]# 写出数据
In [143]: df.to_csv("foo.csv")对数据进行操作
对数据操作包括增(创建),删,改,查。
增加数据(创建数据)
相比较Series,我们更常使用DataFrame数据类型,常使用的创建DataFrame类型有两种,一种是使用data创建(注意data得是一个二维list/array等),一种是使用字典创建。
1. 使用data创建DF
# 使用data导入
In [5]: dates = pd.date_range("20130101", periods=6)
In [6]: dates
Out[6]:
DatetimeIndex(['2013-01-01', '2013-01-02', '2013-01-03', '2013-01-04',
'2013-01-05', '2013-01-06'],
dtype='datetime64[ns]', freq='D')
In [7]: df = pd.DataFrame(data=np.random.randn(6, 4), index=dates, columns=list("ABCD"))
In [8]: df
Out[8]:
A B C D
2013-01-01 0.469112 -0.282863 -1.509059 -1.135632
2013-01-02 1.212112 -0.173215 0.119209 -1.044236
2013-01-03 -0.861849 -2.104569 -0.494929 1.071804
2013-01-04 0.721555 -0.706771 -1.039575 0.271860
2013-01-05 -0.424972 0.567020 0.276232 -1.087401
2013-01-06 -0.673690 0.113648 -1.478427 0.5249882. 使用字典创建DF
# 使用字典
In [9]: df2 = pd.DataFrame(
...: {
...: "A": 1.0,
...: "B": pd.Timestamp("20130102"),
...: "C": pd.Series(1, index=list(range(4)), dtype="float32"),
...: "D": np.array([3] * 4, dtype="int32"),
...: "E": pd.Categorical(["test", "train", "test", "train"]),
...: "F": "foo",
...: }
...: )
...:
In [10]: df2
Out[10]:
A B C D E F
0 1.0 2013-01-02 1.0 3 test foo
1 1.0 2013-01-02 1.0 3 train foo
2 1.0 2013-01-02 1.0 3 test foo
3 1.0 2013-01-02 1.0 3 train foo3. 增加一行数据
1)使用loc在行尾增加
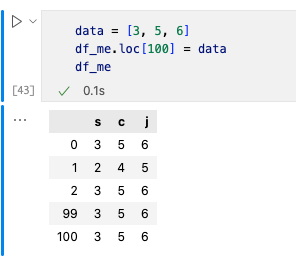
增加一行数据的方法有loc, iloc, append, concat, merge。这里介绍一下loc,loc[index]是在一行的最后增加数据。但是你需要注意loc[index]中的index,如果与已出现过的index相同,则会覆盖原先index行,若不相同则才会增加一行数据。
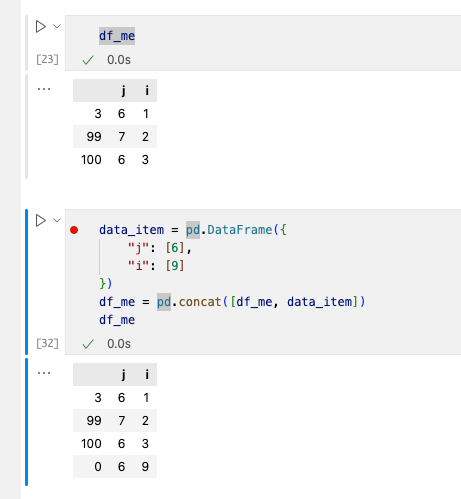
2)使用concat将两个DF合并
concat()也是一个增加数据常用的方法,常见于两个表的拼接与爬虫使用中,作用类似于append(),但是append()将在不久后被pandas舍弃,所以还是推荐使用concat()。
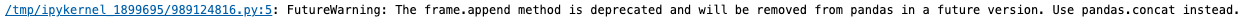
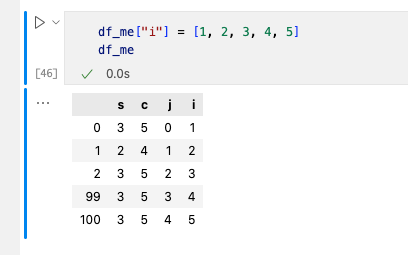
4. 增加一列数据
增加一列数据的方法直接用[]便可,例子如下:
Series用的比较少,案例如下:
In [3]: s = pd.Series([1, 3, 5, np.nan, 6, 8]) In [4]: s Out[4]: 0 1.0 1 3.0 2 5.0 3 NaN 4 6.0 5 8.0 dtype: float64
删除数据
对于删除数据,我们使用drop()方法,并指定参数为index(行)或者column(列)
1. 删除一行数据
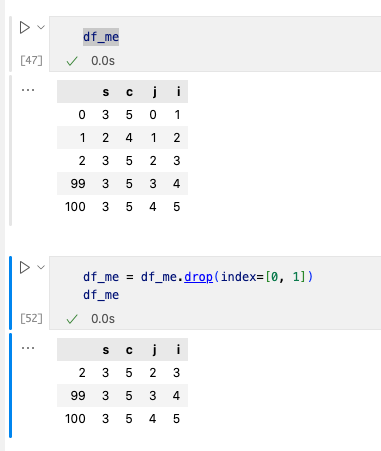
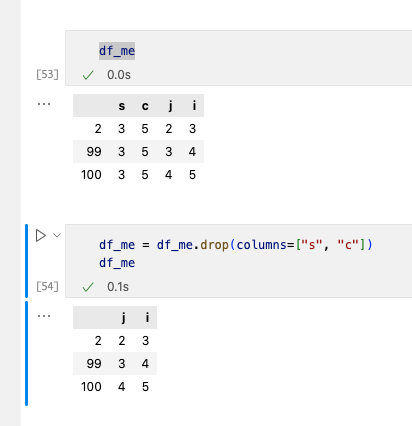
2. 删除一列数据
改动数据
改动一行,列数据常用loc()和[]方法。
1. 改动一行数据
改动一行我们使用loc[]=[…]进行更改。
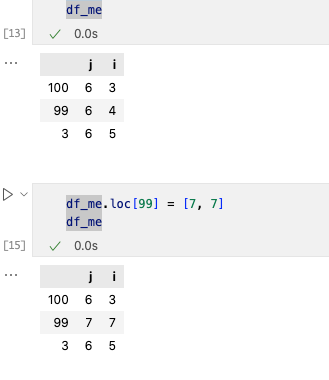
2. 改动一列数据
改动一列数据我们使用[]进行更改。
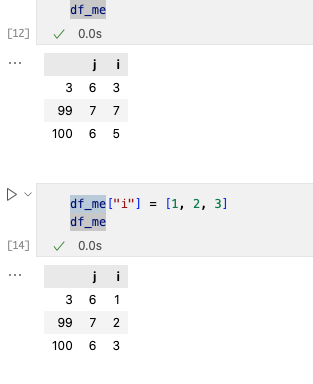
查找数据
在查找数据的时候,我们常使用[]来查看行列数据,配合.T来将矩阵转置。也可以使用head(),tail()来查看前几行和后几行数据。
1. 查看特定行数据
使用.loc[index]来查看特定行数据,或者[]。建议使用.loc[]方法或者.iloc[]方法,loc[]通过行的名字寻找,iloc[]通过索引寻找。
使用类似[0:2]来查看特定行数据,和python中list使用类似。这个方法其实是调用了__getitem__()方法。

2. 查看特定列数据
我们需要使用两层[]嵌套来访问数据,例如[ [“j”, “i”] ]。
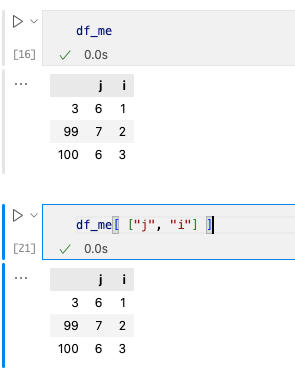
3. 查看特定元素
确定第几行第几列后,使用.loc()方法或者.iloc()方法查找。
b = a.loc[ 1, "dir_name" ]
常用操作
数据分析时常用的两个操作,转置和计算统计量。
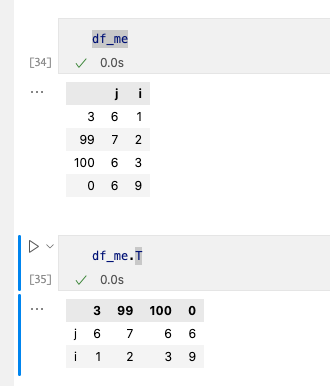
1. 转置
使用.T便可以完成。
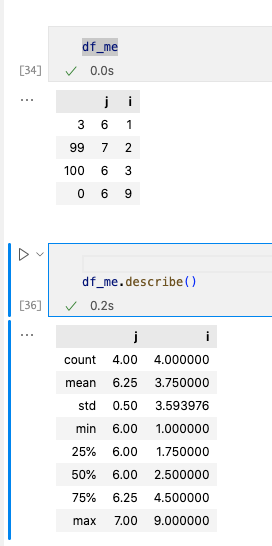
2. 计算统计量
使用.describe()。
3. 舍弃一列中多余重复数据
使用.drop_duplicates()
id_df = self.frames_meta_sub[['time_idx', 'pos_idx', 'slice_idx']].drop_duplicates()
4. 将特定列转成numpy后处理
使用.to_numpy()方法将你所选择的数据全部转成二维的或者一维的ndarray,需要注意的是to_numpy()并不仅仅局限于数字,字符串也是可以转换的(虽然这样开销比较大),ndarray能存储字符串,这会让你处理数据的过程变得异常简单。有几个维度取决于你取了几行或者几列。
df = df[ ["channel"] ] ar = df.to_numpy()
5. 取出dataframe中特定位置的值
要取出 DataFrame 中特定位置的值,可以使用 .loc 或 .iloc 方法,具体取决于您想要使用的索引类型。
如果您使用标签索引(例如,行和列都使用标签名称),则可以使用 .loc 方法。例如,如果您有一个名为 df 的 DataFrame,它具有行标签为 row_label,列标签为 column_label 的元素,则可以使用以下代码获取该元素的值:
value = df.loc[row_label, column_label]
如果您使用整数位置索引(例如,行和列都使用整数位置),则可以使用 .iloc 方法。例如,如果您有一个名为 df 的 DataFrame,它具有第一个行和第一个列的元素,则可以使用以下代码获取该元素的值:
value = df.iloc[0, 0]
请注意,索引从零开始,因此第一个行和第一个列的位置为 0。
到此这篇关于10分钟快速入门Pandas库的文章就介绍到这了,更多相关Pandas库作用内容请搜索码农之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持码农之家!








