给网友们整理相关的编程文章,网友屠华池根据主题投稿了本篇教程内容,涉及到python、迭代器、函数、对python中的高效迭代器函数详解相关内容,已被888网友关注,如果对知识点想更进一步了解可以在下方电子资料中获取。
对python中的高效迭代器函数详解
python中内置的库中有个itertools,可以满足我们在编程中绝大多数需要迭代的场合,当然也可以自己造轮子,但是有现成的好用的轮子不妨也学习一下,看哪个用的顺手~
首先还是要先import一下:
#import itertools from itertools import * #最好使用时用上面那个,不过下面的是为了演示比较 常用的,所以就直接全部导入了
一.无限迭代器:

由于这些都是无限迭代器,因此使用的时候都要设置终止条件,不然会一直运行下去,也就不是我们想要的结果了。
1、count()
可以设置两个参数,第一个参数为起始点,且包含在内,第二个参数为步长,如果不设置第二个参数则默认步长为1
for x in count(10,20): if x < 200: print x
def count(start=0, step=1): # count(10) --> 10 11 12 13 14 ... # count(2.5, 0.5) -> 2.5 3.0 3.5 ... n = start while True: yield n n += step
2、cycle()
可以设置一个参数,且只接受可以迭代的参数,如列表,元组,字符串。。。,该函数会对可迭代的所有元素进行循环:
for i,x in enumerate(cycle('abcd')):
if i < 5:
print x
def cycle(iterable):
# cycle('ABCD') --> A B C D A B C D A B C D ...
saved = []
for element in iterable:
yield element
saved.append(element)
while saved:
for element in saved:
yield element
3、repeat()
可以设置两个参数,其中第一个参数要求可迭代,第二个参数为重复次数,第二个参数如不设置则无限循环,一般来说使用时都会设置第二个参数,用来满足预期重复次数后终止:
#注意如果不设置第二个参数notebook运行可能会宕机 for x in repeat(['a','b','c'],10): print x
二.有限迭代器
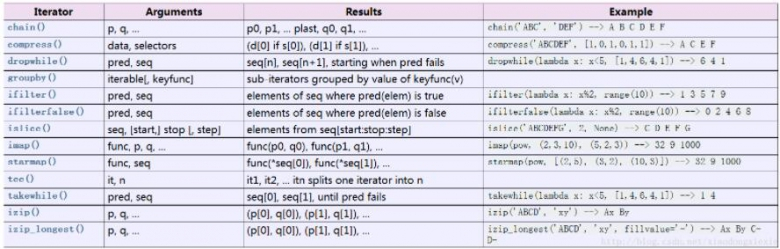
1、chain()
可以接受不定个数个可迭代参数,不要求可迭代参数类型相同,会返回一个列表,这个类似于list的extend,不过不同点是list的extend是对原变量进行改变不返回,而chain则是就地改变并返回:
list(chain(range(4),range(5)))
list(chain(range(4),'abc'))
list(chain(('a','b','c'),'nihao',['shijie','zhongguo']))
def chain(*iterables):
# chain('ABC', 'DEF') --> A B C D E F
for it in iterables:
for element in it:
yield element
2.compress()
第一个参数为可迭代类型,第二个参数为0和1的集合,两者长度可以不等,
这个暂时不知道可以用在哪里、
list(compress(['a','b','c','d','e'],[0,1,1,1,0,1]))
def compress(data, selectors):
# compress('ABCDEF', [1,0,1,0,1,1]) --> A C E F
return (d for d, s in izip(data, selectors) if s)
3.dropwhile()
接受两个参数,第一个参数为一个判断类似于if语句的函数,丢弃满足的项,直到第一个不满足的项出现时停止丢弃,就是
#伪代码大概是这个样子的 if condition: drop element while not condition: stop drop
list(dropwhile(lambda x:x>5,range(10,0,-1)))
def dropwhile(predicate, iterable): # dropwhile(lambda x: x<5, [1,4,6,4,1]) --> 6 4 1 iterable = iter(iterable) for x in iterable: if not predicate(x): yield x break for x in iterable: yield x
4.groupby
对给定可迭代集合(有重复元素)进行分组,返回的是一个元组,元组的第一个为分组的元素,第二个为分组的元素集合,还是看代码吧:
for x,y in groupby(['a','a','b','b','b','b','c','d','e','e']): print x print list(y) print '' out: a ['a', 'a'] b ['b', 'b', 'b', 'b'] c ['c'] d ['d'] e ['e', 'e']
class groupby(object):
# [k for k, g in groupby('AAAABBBCCDAABBB')] --> A B C D A B
# [list(g) for k, g in groupby('AAAABBBCCD')] --> AAAA BBB CC D
def __init__(self, iterable, key=None):
if key is None:
key = lambda x: x
self.keyfunc = key
self.it = iter(iterable)
self.tgtkey = self.currkey = self.currvalue = object()
def __iter__(self):
return self
def next(self):
while self.currkey == self.tgtkey:
self.currvalue = next(self.it) # Exit on StopIteration
self.currkey = self.keyfunc(self.currvalue)
self.tgtkey = self.currkey
return (self.currkey, self._grouper(self.tgtkey))
def _grouper(self, tgtkey):
while self.currkey == tgtkey:
yield self.currvalue
self.currvalue = next(self.it) # Exit on StopIteration
self.currkey = self.keyfunc(self.currvalue)
5.ifilter()
这个有点像是filter函数了,不过有点不同,filter返回的是一个完成后的列表,而ifilter则是一个生成器,使用的yield
#这样写只是为了更清楚看到输出,其实这么写就跟filter用法一样了,体现不到ifilter的优越之处了 list(ifilter(lambda x:x%2,range(10)))
6.ifilterfalse()
这个跟ifilter用法很像,只是两个是相反数的关系。
list(ifilterfalse(lambda x:x%2,range(10)))
7.islice()
接受三个参数,可迭代参数,起始切片点,结束切片点,最少给定两个参数,当只有两个参数为默认第二个参数为结束切片点:
In: list(islice(range(10),2,None)) Out: [2, 3, 4, 5, 6, 7, 8, 9] In: list(islice(range(10),2)) Out: [0, 1]
8.imap()
接受参数个数跟目标函数有关:
#接受两个参数时 list(imap(abs,range(-5,5))) #接受三个参数时 list(imap(pow,range(-5,5),range(10))) #接受四个参数时 list(imap(lambda x,y,z:x+y+z,range(10),range(10),range(10)))
9.starmap()
这个是imap的变异,即只接受两个参数,目标函数会作用在第二个参数集合中、
in: list(starmap(pow,[(1,2),(2,3)])) out: [1, 8]
10.tee()
接受两个参数,第一个参数为可迭代类型,第二个为int,如果第二个不指定则默认为2,即重复两次,有点像是生成器repeat的生成器类型,
这个就有意思了,是双重生成器输出:
for x in list(tee('abcde',3)):
print list(x)
11.takewhile()
这个有点跟dropwhile()很是想象,一个是丢弃,一个是拿取:
伪代码为:
if condition: take this element while not condition: stop take
eg:
in: list(takewhile(lambda x:x<10,(1,9,10,11,8))) out: [1, 9]
12.izip()
这个跟imap一样,只不过imap是针对map的生成器类型,而izip是针对zip的:
list(izip('ab','cd'))
13.izip_longest
针对izip只截取最短的,这个是截取最长的,以None来填充空位:
list(izip_longest('a','abcd'))
三、组合迭代器
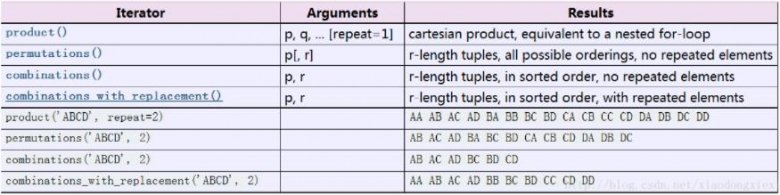
1.product()
这个有点像是多次使用for循环,两者可以替代。
list(product(range(10),range(10))) #本质上是这种的生成器模式 L = [] for x in range(10): for y in range(10): L.append((x,y))
2.permutations()
接受两个参数,第二个参数不设置时输出的没看出来是什么鬼,
第二个参数用来控制生成的元组的元素个数,而输出的元组中最后一个元素是打乱次序的,暂时也不知道可以用在哪
list(permutations(range(10),2))
3.combinations()
用来排列组合,抽样不放回,第二个参数为参与排列组合的个数
list(combinations('abc',2))
def combinations(iterable, r):
# combinations('ABCD', 2) --> AB AC AD BC BD CD
# combinations(range(4), 3) --> 012 013 023 123
pool = tuple(iterable)
n = len(pool)
if r > n:
return
indices = range(r)
yield tuple(pool[i] for i in indices)
while True:
for i in reversed(range(r)):
if indices[i] != i + n - r:
break
else:
return
indices[i] += 1
for j in range(i+1, r):
indices[j] = indices[j-1] + 1
yield tuple(pool[i] for i in indices)
def combinations(iterable, r): pool = tuple(iterable) n = len(pool) for indices in permutations(range(n), r): if sorted(indices) == list(indices): yield tuple(pool[i] for i in indices)
4.combinations_with_replacement()
与上一个的用法不同的是抽样是放回的
def combinations_with_replacement(iterable, r):
# combinations_with_replacement('ABC', 2) --> AA AB AC BB BC CC
pool = tuple(iterable)
n = len(pool)
if not n and r:
return
indices = [0] * r
yield tuple(pool[i] for i in indices)
while True:
for i in reversed(range(r)):
if indices[i] != n - 1:
break
else:
return
indices[i:] = [indices[i] + 1] * (r - i)
yield tuple(pool[i] for i in indices)
def combinations_with_replacement(iterable, r): pool = tuple(iterable) n = len(pool) for indices in product(range(n), repeat=r): if sorted(indices) == list(indices): yield tuple(pool[i] for i in indices)
以上这篇对python中的高效迭代器函数详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持码农之家。

















