给网友们整理相关的编程文章,网友晏敏博根据主题投稿了本篇教程内容,涉及到Spark、Streaming算子、Spark、Streaming、Spark Streaming算子开发实例相关内容,已被829网友关注,下面的电子资料对本篇知识点有更加详尽的解释。
Spark Streaming算子开发实例
Spark Streaming算子开发实例
transform算子开发
transform操作应用在DStream上时,可以用于执行任意的RDD到RDD的转换操作,还可以用于实现DStream API中所没有提供的操作,比如说,DStreamAPI中并没有提供将一个DStream中的每个batch,与一个特定的RDD进行join的操作,DStream中的join算子只能join其他DStream,但是我们自己就可以使用transform操作来实现该功能。
实例:黑名单用户实时过滤
package StreamingDemo
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* 实时黑名单过滤
*/
object TransformDemo {
def main(args: Array[String]): Unit = {
//设置日志级别
Logger.getLogger("org").setLevel(Level.WARN)
val conf = new SparkConf()
.setAppName(this.getClass.getSimpleName)
.setMaster("local[2]")
val ssc = new StreamingContext(conf, Seconds(2))
//创建一个黑名单的RDD
val blackRDD =
ssc.sparkContext.parallelize(Array(("zs", true), ("lisi", true)))
//通过socket从nc中获取数据
val linesDStream = ssc.socketTextStream("Hadoop01", 6666)
/**
* 过滤黑名单用户发言
* zs sb sb sb sb
* lisi fuck fuck fuck
* jack hello
*/
linesDStream
.map(x => {
val info = x.split(" ")
(info(0), info.toList.tail.mkString(" "))
})
.transform(rdd => { //transform是一个RDD->RDD的操作,所以返回值必须是RDD
/**
* 经过leftouterjoin操作之后,产生的结果如下:
* (zs,(sb sb sb sb),Some(true)))
* (lisi,(fuck fuck fuck),some(true)))
* (jack,(hello,None))
*/
val joinRDD = rdd.leftOuterJoin(blackRDD)
//如果是Some(true)的,说明就是黑名单用户,如果是None的,说明不在黑名单内,把非黑名单的用户保留下来
val filterRDD = joinRDD.filter(x => x._2._2.isEmpty)
filterRDD
})
.map(x=>(x._1,x._2._1)).print()
ssc.start()
ssc.awaitTermination()
}
}
测试
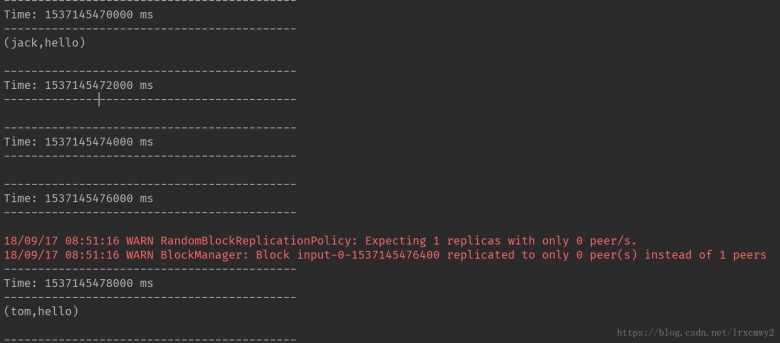
启动nc,传入用户及其发言信息

可以看到程序实时的过滤掉了在黑名单里的用户发言
updateStateByKey算子开发
updateStateByKey算子可以保持任意状态,同时不断有新的信息进行更新,这个算子可以为每个key维护一份state,并持续不断的更新state。对于每个batch来说,Spark都会为每个之前已经存在的key去应用一次State更新函数,无论这个key在batch中是否有新的值,如果State更新函数返回的值是none,那么这个key对应的state就会被删除;对于新出现的key也会执行state更新函数。
要使用该算子,必须进行两个步骤
- 定义state——state可以是任意的数据类型
- 定义state更新函数——用一个函数指定如何使用之前的状态,以及从输入流中获取新值更新状态
注意:updateStateByKey操作,要求必须开启Checkpoint机制
实例:基于缓存的实时WordCount
package StreamingDemo
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* 基于缓存的实时WordCount,在全局范围内统计单词出现次数
*/
object UpdateStateByKeyDemo {
def main(args: Array[String]): Unit = {
//设置日志级别
Logger.getLogger("org").setLevel(Level.WARN)
/**
* 如果没有启用安全认证或者从Kerberos获取的用户为null,那么获取HADOOP_USER_NAME环境变量,
* 并将它的值作为Hadoop执行用户设置hadoop username
* 这里实验了一下在没有启用安全认证的情况下,就算不显式添加,也会自动获取我的用户名
*/
//System.setProperty("HADOOP_USER_NAME","Setsuna")
val conf = new SparkConf()
.setAppName(this.getClass.getSimpleName)
.setMaster("local[2]")
val ssc = new StreamingContext(conf, Seconds(2))
//设置Checkpoint存放的路径
ssc.checkpoint("hdfs://Hadoop01:9000/checkpoint")
//创建输入DStream
val lineDStream = ssc.socketTextStream("Hadoop01", 6666)
val wordDStream = lineDStream.flatMap(_.split(" "))
val pairsDStream = wordDStream.map((_, 1))
/**
* state:代表之前的状态值
* values:代表当前batch中key对应的values值
*/
val resultDStream =
pairsDStream.updateStateByKey((values: Seq[Int], state: Option[Int]) => {
//当state为none,表示没有对这个单词做统计,则返回0值给计数器count
var count = state.getOrElse(0)
//遍历values,累加新出现的单词的value值
for (value <- values) {
count += value
}
//返回key对应的新state,即单词的出现次数
Option(count)
})
//在控制台输出
resultDStream.print()
ssc.start()
ssc.awaitTermination()
}
}
测试
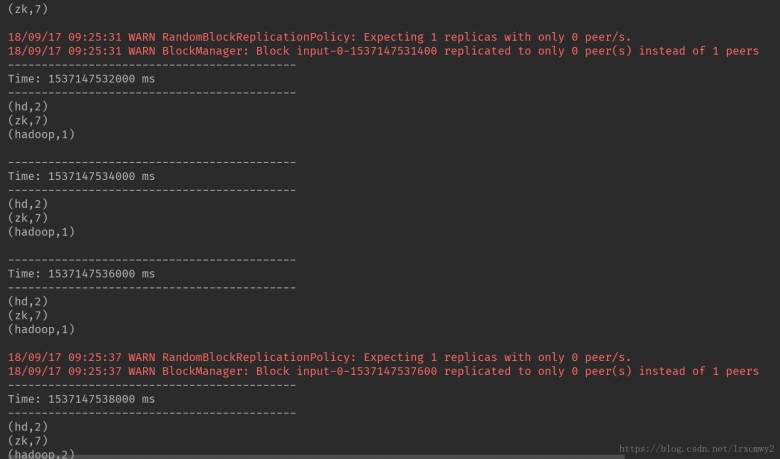
开启nc,输入单词

控制台实时输出的结果
window滑动窗口算子开发
Spark Streaming提供了滑动窗口操作的支持,可以对一个滑动窗口内的数据执行计算操作
在滑动窗口中,包含批处理间隔、窗口间隔、滑动间隔
- 对于窗口操作而言,在其窗口内部会有N个批处理数据
- 批处理数据的大小由窗口间隔决定,而窗口间隔指的就是窗口的持续时间,也就是窗口的长度
- 滑动时间间隔指的是经过多长时间窗口滑动一次,形成新的窗口,滑动间隔默认情况下和批处理时间间隔的相同
注意:滑动时间间隔和窗口时间间隔的大小一定得设置为批处理间隔的整数倍
用一个官方的图来作为说明
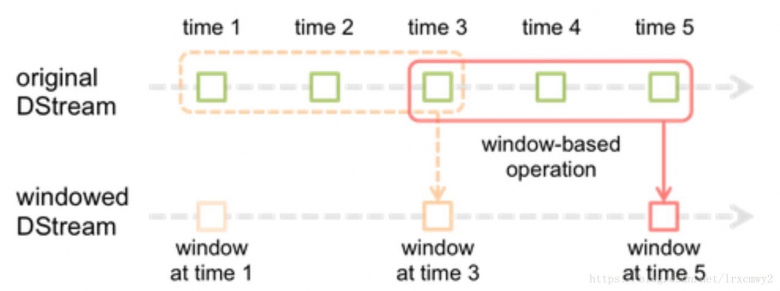
批处理间隔是1个时间单位,窗口间隔是3个时间单位,滑动间隔是2个时间单位。对于初始的窗口time1-time3,只有窗口间隔满足了才触发数据的处理。所以滑动窗口操作都必须指定两个参数,窗口长度和滑动时间间隔。在Spark Streaming中对滑动窗口的支持是比Storm更加完善的。
Window滑动算子操作
| 算子 | 描述 |
| window() | 对每个滑动窗口的数据执行自定义的计算 |
| countByWindow() | 对每个滑动窗口的数据执行count操作 |
| reduceByWindow() | 对每个滑动窗口的数据执行reduce操作 |
| reduceByKeyAndWindow() | 对每个滑动窗口的数据执行reduceByKey操作 |
| countByValueAndWindow() | 对每个滑动窗口的数据执行countByValue操作 |
reduceByKeyAndWindow算子开发
实例:在线热点搜索词实时滑动统计
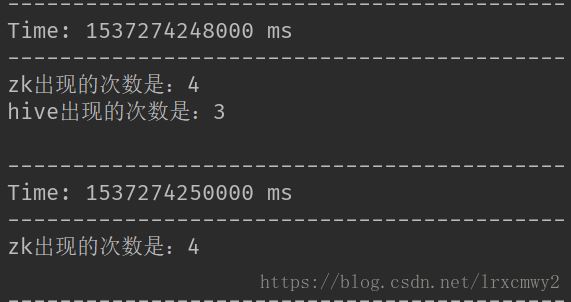
每隔2秒钟,统计最近5秒钟的搜索词中排名最靠前的3个搜索词以及出现次数
package StreamingDemo
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* 需求:每隔2秒钟,统计最近5秒钟的搜索词中排名最靠前的3个搜索词以及出现次数
*/
object ReduceByKeyAndWindowDemo {
def main(args: Array[String]): Unit = {
//设置日志级别
Logger.getLogger("org").setLevel(Level.WARN)
//基础配置
val conf = new SparkConf()
.setAppName(this.getClass.getSimpleName)
.setMaster("local[2]")
//批处理间隔设置为1s
val ssc = new StreamingContext(conf, Seconds(1))
val linesDStream = ssc.socketTextStream("Hadoop01", 6666)
linesDStream
.flatMap(_.split(" ")) //根据空格来做分词
.map((_, 1)) //返回(word,1)
.reduceByKeyAndWindow(
//定义窗口如何计算的函数
//x代表的是聚合后的结果,y代表的是这个Key对应的下一个需要聚合的值
(x: Int, y: Int) => x + y,
//窗口长度为5秒
Seconds(5),
//窗口时间间隔为2秒
Seconds(2)
)
.transform(rdd => { //transform算子对rdd做处理,转换为另一个rdd
//根据Key的出现次数来进行排序,然后降序排列,获取最靠前的3个搜索词
val info: Array[(String, Int)] = rdd.sortBy(_._2, false).take(3)
//将Array转换为resultRDD
val resultRDD = ssc.sparkContext.parallelize(info)
resultRDD
})
.map(x => s"${x._1}出现的次数是:${x._2}")
.print()
ssc.start()
ssc.awaitTermination()
}
}
测试结果
DStream Output操作概览
Spark Streaming允许DStream的数据输出到外部系统,DSteram中的所有计算,都是由output操作触发的,foreachRDD输出操作,也必须在里面对RDD执行action操作,才能触发对每一个batch的计算逻辑。
| 转换 | 描述 |
| print() | 在Driver中打印出DStream中数据的前10个元素。主要用于测试,或者是不需要执行什么output操作时,用于简单触发一下job。 |
|
saveAsTextFiles(prefix, [suffix]) |
将DStream中的内容以文本的形式保存为文本文件,其中每次批处理间隔内产生的文件以prefix-TIME_IN_MS[.suffix]的方式命名。 |
|
saveAsObjectFiles(prefix , [suffix]) |
将DStream中的内容按对象序列化并且以SequenceFile的格式保存。其中每次批处理间隔内产生的文件以prefix-TIME_IN_MS[.suffix]的方式命名。 |
|
saveAsHadoopFiles(pref ix, [suffix]) |
将DStream中的内容以文本的形式保存为Hadoop文件,其中每次批处理间隔内产生的文件 以prefix-TIME_IN_MS[.suffix]的方式命名。 |
| foreachRDD(func) |
最基本的输出操作,将func函数应用于DStream中的RDD上,这个操作会输出数据到外部系 统,比如保存RDD到文件或者网络数据库等。需要注意的是func函数是在运行该streaming 应用的Driver进程里执行的。 |
foreachRDD算子开发
foreachRDD是最常用的output操作,可以遍历DStream中的每个产生的RDD并进行处理,然后将每个RDD中的数据写入外部存储,如文件、数据库、缓存等,通常在其中针对RDD执行action操作,比如foreach
使用foreachRDD操作数据库
通常在foreachRDD中都会创建一个Connection,比如JDBC Connection,然后通过Connection将数据写入外部存储
误区一:在RDD的foreach操作外部创建Connection
dstream.foreachRDD { rdd =>
val connection=createNewConnection()
rdd.foreach { record => connection.send(record)
}
}
这种方式是错误的,这样的方式会导致Connection对象被序列化后被传输到每一个task上,但是Connection对象是不支持序列化的,所以也就无法被传输
误区二:在RDD的foreach操作内部创建Connection
dstream.foreachRDD { rdd =>
rdd.foreach { record =>
val connection = createNewConnection()
connection.send(record)
connection.close()
}
}
这种方式虽然是可以的,但是执行效率会很低,因为它会导致对RDD中的每一条数据都创建一个Connection对象,通常Connection对象的创建都是很消耗性能的
合理的方式
- 第一种:使用RDD的foreachPartition操作,并且在该操作内部创建Connection对象,这样就相当于为RDD的每个partition创建一个Connection对象,节省了很多资源
- 第二种:自己手动封装一个静态连接池,使用RDD的foreachPartition操作,并且在该操作内部从静态连接池中,通过静态方法获取到一个连接,连接使用完之后再放回连接池中。这样的话,可以在多个RDD的partition之间复用连接了
实例:实时全局统计WordCount,并将结果保存到MySQL数据库中
MySQL数据库建表语句如下
CREATE TABLE wordcount ( word varchar(100) CHARACTER SET utf8 NOT NULL, count int(10) NOT NULL, PRIMARY KEY (word) ) ENGINE=InnoDB DEFAULT CHARSET=latin1;
在IDEA中添加mysql-connector-java-5.1.40-bin.jar

代码如下
连接池的代码,其实一开始有想过用静态块来写个池子直接获取,但是如果考虑到池子宽度不够用的问题,这样的方式其实更好,一开始,实例化一个连接池出来,被调用获取连接,当连接全部都被获取了的时候,池子空了,就再实例化一个池子出来
package StreamingDemo
import java.sql.{Connection, DriverManager, SQLException}
import java.util
object JDBCManager {
var connectionQue: java.util.LinkedList[Connection] = null
/**
* 从数据库连接池中获取连接对象
* @return
*/
def getConnection(): Connection = {
synchronized({
try {
//如果连接池是空的,那么就实例化一个Connection类型的链表
if (connectionQue == null) {
connectionQue = new util.LinkedList[Connection]()
for (i <- 0 until (10)) {
//生成10个连接,并配置相关信息
val connection = DriverManager.getConnection(
"jdbc:mysql://Hadoop01:3306/test?characterEncoding=utf-8",
"root",
"root")
//将连接push进连接池
connectionQue.push(connection)
}
}
} catch {
//捕获异常并输出
case e: SQLException => e.printStackTrace()
}
//如果连接池不为空,则返回表头元素,并将它在链表里删除
return connectionQue.poll()
})
}
/**
* 当连接对象用完后,需要调用这个方法归还连接
* @param connection
*/
def returnConnection(connection: Connection) = {
//插入元素
connectionQue.push(connection)
}
def main(args: Array[String]): Unit = {
//main方法测试
getConnection()
println(connectionQue.size())
}
}
wordcount代码
package StreamingDemo
import org.apache.log4j.{Level, Logger}
import org.apache.spark.{SparkConf, streaming}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object ForeachRDDDemo {
def main(args: Array[String]): Unit = {
//设置日志级别,避免INFO信息过多
Logger.getLogger("org").setLevel(Level.WARN)
//设置Hadoop的用户,不加也可以
System.setProperty("HADOOP_USER_NAME", "Setsuna")
//Spark基本配置
val conf = new SparkConf()
.setAppName(this.getClass.getSimpleName)
.setMaster("local[2]")
val ssc = new StreamingContext(conf, streaming.Seconds(2))
//因为要使用updateStateByKey,所以需要使用checkpoint
ssc.checkpoint("hdfs://Hadoop01:9000/checkpoint")
//设置socket,跟nc配置的一样
val linesDStream = ssc.socketTextStream("Hadoop01", 6666)
val wordCountDStream = linesDStream
.flatMap(_.split(" ")) //根据空格做分词
.map((_, 1)) //生成(word,1)
.updateStateByKey((values: Seq[Int], state: Option[Int]) => {
//实时更新状态信息
var count = state.getOrElse(0)
for (value <- values) {
count += value
}
Option(count)
})
wordCountDStream.foreachRDD(rdd => {
if (!rdd.isEmpty()) {
rdd.foreachPartition(part => {
//从连接池中获取连接
val connection = JDBCManager.getConnection()
part.foreach(data => {
val sql = //往wordcount表中插入wordcount信息,on duplicate key update子句是有则更新无则插入
s"insert into wordcount (word,count) " +
s"values ('${data._1}',${data._2}) on duplicate key update count=${data._2}"
//使用prepareStatement来使用sql语句
val pstmt = connection.prepareStatement(sql)
pstmt.executeUpdate()
})
//在连接处提交完数据后,归还连接到连接池
JDBCManager.returnConnection(connection)
})
}
})
ssc.start()
ssc.awaitTermination()
}
}
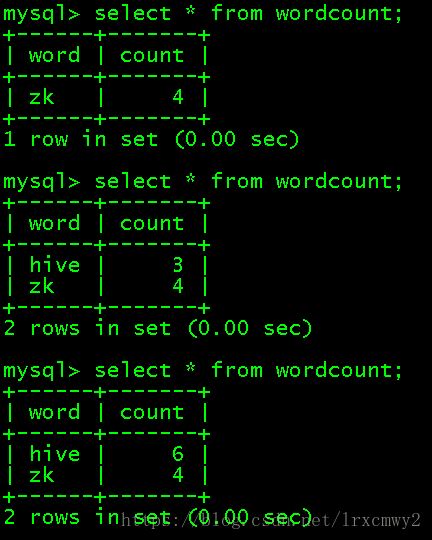
打开nc,输入数据

在另一个终端对wordcount的结果进行查询,可以发现是实时发生变化的
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持码农之家。