本站收集了一篇相关的编程文章,网友农朋义根据主题投稿了本篇教程内容,涉及到python、list、输出、10个元素、python list输出10个元素的方法相关内容,已被822网友关注,如果对知识点想更进一步了解可以在下方电子资料中获取。
python list输出10个元素的方法
怎么在python中输出一个列表中出现次数前十的元素
打印列表中出现前十的元素,可以利用列表的count属性,可以计数,然后根据数量多少排序 来输出元素
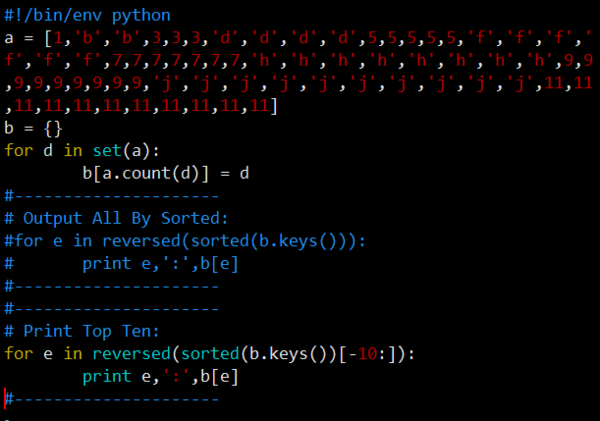
a = [1,'b','b',3,3,3,'d','d','d','d',5,5,5,5,5,'f','f','f','
f','f','f',7,7,7,7,7,7,7,'h','h','h','h','h','h','h','h',9,9
,9,9,9,9,9,9,9,'j','j','j','j','j','j','j','j','j','j',11,11
,11,11,11,11,11,11,11,11,11]
b = {} #定义空字典
for d in set(a): #去重复的值,set
b[a.count(d)] = d #去重后做计数,把数量和值写到字典b
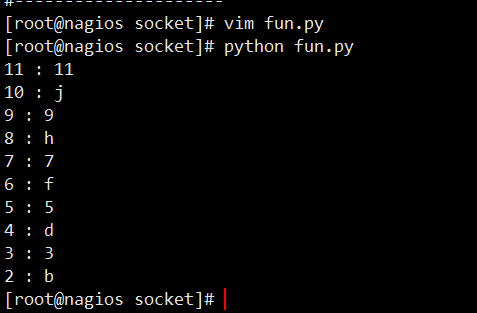
for e in reversed(sorted(b.keys())[-10:]):
print e,':',b[e] #排序列表键值并取后10个(数量最大的10个),翻转后打印出数量与值。
t=[1,2,3,4,5,6,1,2,3,4,5,1,2,3,4,1,2,3,1,2,1,6,6,6,6,6,6,6,6]
d={}
for i in set(t):
d[i]=t.count(i)
t=sorted(d.iteritems(), key=lambda x : x[1], reverse=True)
j=1
for i in t:
print i[0]
按出现次数大小 输出,你取前10个就可以啦~

















